灵巧的设计,让BI更轻快
本文从BI生成 sql 的原理解析入手,结合实际项目中报表设计优化的典型案例,系统讲解了BI分析表设计中性能攸关的设计要素。
1. 理解BI分析表的sql
1.1 单主题sql
一张分析单主题表的典型sql语句如下:
SELECT id,avg(sal) avgsal
FROM table
WHERE id<>"0000"
GROUP BY id
Having avg(sal)>5000
ORDER BY avgsal
这段语句中的粗黑体是sql语句的保留关键字,他们是sql语句的主体骨架,蓝色部分是查询统计的具体数据库表、字段、过滤条件、分组和排序依据;将蓝色部分"翻译"成BI分析表中的设计元素后,sql语句如下:
SELECT 表元表达式
FROM 主题表
WHERE 过滤条件 (含表元、维表元、主题集过滤条件及数据期条件)
GROUPBY 维表元(带下钻级次)
HAVING 结果集过滤
ORDERBY 排序依据
可以很清楚地看到,报表工程师们在制作分析表,设计报表和表元的各种属性时,其实是在间接地编写着BI分析报表的sql;因此BI中sql语句性能的好坏,报表工程师有很大的决定权。
1.2 多主题sql
如果分析表的数据来源于多个主题,BI分析表的sql需要将多张主题表连接;典型的sql有两种:
1.2.1 先分组后连接
......
(SELECT 表元表达式
FROM 主题表1
WHERE 过滤条件(含表元、维表元、主题集过滤条件及数据期条件)
GROUPBY 维表元 (带下钻级次)
) T1
JOIN (支持INNER JOIN、RIGHT JOIN、LEFT JOIN、UNION ALL)
(SELECT 表元表达式
FROM 主题表2
WHERE 过滤条件(含表元、维表元、主题集过滤条件及数据期条件)
GROUPBY 维表元(带下钻级次)
)T2
ON T1.维表元字段 = T2.维表元字段 ......
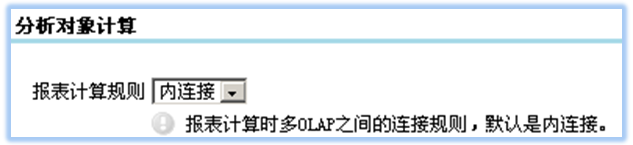
红色部分是相对单主题sql新增加的典型元素;其中join方式可以是内连接、左连接、右连接、全连接,具体是哪种取决于主题集属性中的OLAP连接计算规则,如图:
1.2.2 先连接后分组
有些分析需要在两个主题的明细数据上进行运算和关联,此时不得不在sql中将两个主题表先连接再分组统计;其典型的sql如下:
......
SELECT主题表1. 表元表达式1 ,主题表1. 表元表达式2 ,主题表2. 表元表达式1
FROM 主题表1
JOIN(支持INNER JOIN、RIGHT JOIN、LEFT JOIN、UNION ALL)
主题表2
ON主题表1.关联字段1=主题表2.关联字段1...
WHERE 过滤条件(含表元、维表元、主题集过滤条件及数据期条件)
GROUPBY 维表元(带下钻级次) ......
从表面上看,此处的红色部分新增元素好像和【先分组后连接】差不多,是不是两种sql性能相当呢?
让我们一起考虑一下这样的场景,主题表A和B均有10w行明细数据,需要按行业大类(20行)统计来自A和B的某些指标;
【先连接后分组】需要首先将两个10w行规模的明细表join起来,之后再按行业分组;
【先分组后连接】会分别在主题A和主题B上分组后再按行业大类join,此时连接的仅仅只是两个20行的子表;性能相比,孰优孰劣,一目了然!
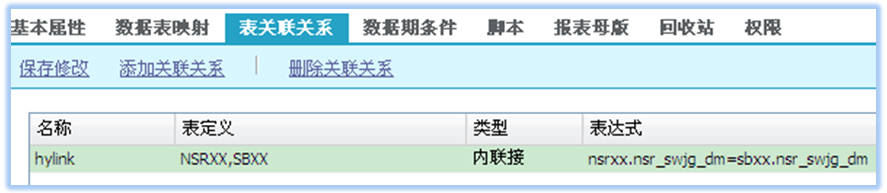
【先连接后分组】方式下,主题明细数据表连接的方式由报表设计中的什么元素决定呢?请看下图,是主题集属性中的表关联设置:
1.3 为什么会多sql?
查看分析表的【详细信息】,有时我们会发现为了计算一张分析表,BI生成了多个子sql嵌套和连接,或者干脆是多个独立的sql,为什么会这样呢?
要弄清这个问题,咱们得先回头再看看之前提到的sql语句:
SELECT表元表达式
FROM 主题表
WHERE 过滤条件(含表元、维表元、主题集过滤条件及数据期条件)
GROUPBY 维表元(带下钻级次)
HAVING 结果集过滤
ORDERBY 排序依据
一个这样的Sql语句可以查询出满足where子句条件的一批指标,如果有指标虽然来自同一个主题,但过滤条件不一样,还能用这一个sql一并统计出来吗?
1.3.1 过滤条件不统一
假设现在需要统计主题表1中的多个指标,对zb1,zb2zbm的统计sql如下:
SELECT zb1,zb2...zbm
FROM 主题表1
WHERE filter1
主题表1的【zbn】也需要统计分析,其过滤条件是filter2,和其他指标zb1,zb2都不一样,那么对zbn的统计能和zb1,zb2等指标一起放在一个sql中吗?
答案很显然,不能!否则算出来的zbn就是filter1过滤后的统计值,而不是分析需求filter2的。
因此,如果在BI分析表上我们为表元zbn设置了特殊的过滤条件,BI的sql一定需要单独为这个指标生成一个子sql,比如:
SELECT zbn
FROM 主题表1
WHERE filter2
1.3.2 连接方式不统一
在sql元素中,除了过滤条件之外,还有连接方式的不统一也会造成BI生成多个子sql。正常情况下,假设A和B主题表连接分析的sql如下:
SELECT主题表A.zb ...主题表B.zb1 ,主题表B.zb2
FROM 主题表AINNERJ OIN主题表B
ON主题表A.关联字段1=主题表B.关联字段1
若将B的zb1,zb2设置为左连接,将B的zb3,设置成右连接,由于连接方式不同,无论是【先分组后连接】还是【先连接后分组】,这两张主题表的连接都必须按指标的连接方式拆分为两次join;如下:
(SELECT主题表A.zb ,主题表B.zb1 ,主题表B.zb2
FROM 主题表ALEFT JOIN主题表B
ON 主题表A.关联字段1=主题表B.关联字段1 )
和
(SELECT主题表A.zb,... 主题表B.zb3
FROM 主题表A
RIGHTJOIN主题表B
ON 主题表A.关联字段1=主题表B.关联字段1 )
1.3.3 多个独立的分析区
如果在报表设计上设置了多个独立的分析区,BI会为每个分析区单独生成独立的sql语句。因此我们需要注意,多个分析区真有必要独立分开吗?如果可以合并到一起,BI会尽可能用一个sql提交数据库处理,在某些场景下,特别是对数据量巨大的主题表而言,两次查询统计变成一次,性能上将会有不小的提升。
1.3.4 跨表取数
2011-08-02 17:14:10执行查询耗时1秒203毫秒。(内存情况:FREE=134.9M TOTAL=213.9M MAX=910.2M) 2011-08-02 17:14:10构造结果表耗时28毫秒。 2011-08-02 17:14:10计算"ZXDZB_QS全市"耗时1秒232毫秒。(内存情况:FREE=134.9M TOTAL=213.9M MAX=910.2M) 2011-08-02 17:14:10执行查询耗时1秒961毫秒。(内存情况:FREE=132.9M TOTAL=213.9M MAX=910.2M) 2011-08-02 17:14:10构造结果表耗时11毫秒。 2011-08-02 17:14:10计算"ZXDZB_TS庭室"耗时1秒973毫秒。(内存情况:FREE=132.9M TOTAL=213.9M MAX=910.2M) 2011-08-02 17:14:10执行查询耗时1秒184毫秒。(内存情况:FREE=132.9M TOTAL=213.9M MAX=910.2M) 2011-08-02 17:14:10构造结果表耗时16毫秒。 2011-08-02 17:14:10计算"ZXDZB_RY人员"耗时1秒201毫秒。(内存情况:FREE=131M TOTAL=213.9M MAX=910.2M) |
你一定很熟悉这个方框中的信息模式吧?这是BI中一张分析表的详细信息,但是==,为什么在一个分析报表的详细信息中会看到如此多不同报表的sql生成和计算日志? 原来这张分析表使用了跨表取数,为了计算这张报表,系统先触发执行了其他报表的sql,具体详情请参考《tips201106》;这种情形下,虽然本表没有产生多个sql,但是间接地通过计算其他表,也执行了多个独立的sql,造成本表计算时间超长。
1.4 决定性能的sql要素
作为一个报表工程师,在设计报表的过程中,有哪些和sql性能相关的要素是我们可以调控,需要特别关注的呢?基于以上对BI分析表sql的理解,报表工程师们可着重关注如下要素: 1.过滤条件 2.连接模式 3.Sql个数 4.Sql数据量
下面将分别从这几个方面具体谈谈如何优化BI分析报表的设计。
2. 设计要素之1--过滤条件
BI分析表中的过滤条件在报表计算时都会转换成SQL语句中的WHERE条件,在大数据量的情况下,WHERE条件不够优化,会直接导致SQL语句运行效率低下,最直接的表现就是SQL语句执行时没用到索引或者用到的索引不够好。 我们都知道索引在rolap数据仓库中至关重要,好的索引对查询统计分析的性能提升具有不可替代的作用。因此,一个好的where条件会尽可能充分利用好的索引,决不会破坏数据查询走索引的可能。 BI报表的主题集、维表元、指标表元上都可以设置数据期条件和过滤条件,报表工程师们在这些过滤条件中编写的表达式都将直接决定报表sql语句中where子句的质量;什么样的过滤能构成一个质量上乘的where子句?什么样的过滤一定会造成where子句效率的损失?我们在编写BI报表过滤条件时又该注意哪些问题呢?
2.1 杜绝在指标列上使用函数
*Oracle使用索引的原则之一就是: 如果在WHERE条件中的列上使用了函数,就不会使用该列上建立的索引。*
比如: 某张报表,
其参数为:@date_日期,@shour开始小时,@ehour结束小时
主题表SAMPLETIME列为VARCHAR2,
数据格式形如:2010-12-23 12:12:12
优化前的过滤条件为: CHAP_5MIN.SAMPLETIME like@date_^"%and substr(CHAP_5MIN.SAMPLETIME,12,2)>=@shourandsubstr(CHAP_5MIN.SAMPLETIME,12,2)<=@ehour
其中的Where substr(CHAP_5MIN.SAMPLETIME,12,2)>=@shour这个where条件,虽然SAMPLETIME列上建了索引,但查询统计时系统却不会使用该索引,原因就在于sql语句的where过滤条件中在SAMPLETIME列上作了substr的函数运算。
那根据分析需求,确实需要取SAMPLETIME字段列中的部分进行运算,该怎么办呢? 为了能实现时间的比较而又不在指标列上使用函数,优化时可尽量将指标列上的函数转换到与之比较的常量或者参数上,优化后的过滤条件改为: CHAP_5MIN.SAMPLETIME>=to_char(to_date(@date_,"yyyy-mm-dd"),"yyyy-mm-dd")" " @shourand CHAP_5MIN.SAMPLETIME<=to_char(to_date(@date_,"yyyy-mm-dd"),"yyyy-mm-dd")" " @ehour^ 优化后的过滤条件虽然看似繁琐,但产生的SQL很好,有效地用到了索引。
再来看看农发行的一个真实案例:
在主题表AC_HB_DUE_BILL_MONTH_YJH5RISK列PROD_CD上有索引,
原过滤条件写法为: left(AC_HB_DUE_BILL_MONTH_YJH5RISK.PROD_CD,1)>="1" and left(AC_HB_DUE_BILL_MONTH_YJH5RISK.PROD_CD,1)<="3"
由于在列上用了left函数并且使用的是不等运算符,因此BI无法直接优化为like操作,只能将left转换为sql中的substr函数,结果就破坏了走索引的可能性;
优化成: (AC_HB_DUE_BILL_MONTH_YJH5RISK.PROD_CDlike "1%" or AC_HB_DUE_BILL_MONTH_YJH5RISK.PROD_CD like "2%"or AC_HB_DUE_BILL_MONTH_YJH5RISK.PROD_CD like "3%") 后就可以走索引了;在测试环境经过验证,这个过滤所在的分析表刷新速度由原来的7分钟直接提速到了14秒。
2.2 优化过滤条件表达式
2.2.1 索引基本原则
对于SQL语句来说,最起作用的索引一般涉及到:
Where条件中引用的列(优化数据检索性能),Group by、Order by子句中引用的列(优化排序性能),以及多表连接时,连接条件使用的列(优化连接性能)。
因此在设计分析表时需要注意:
1)写过滤条件时,当有多种写法时,尽量使用所引用的主题表列与索引相符的;
2)如果需要排序时,尽量根据已建立索引的列排序;
3)如果发现过滤条件和排序所需要的列没有索引时,可以向数据库工程师提出,让数据库工程师整体评估具体优化方法(创建,修改索引,修改模型等),切忌自行随意增加索引(过多的索引会影响性能)。
不走索引的常见情况如下:
1)表的统计信息过旧(一般常见于10g以前的版本);
2)表很小,数据量少,Oracle的优化器认为不值得走索引;
3)索引列中有NULL值;
4)在索引列上使用函数时不会使用索引,如果一定要使用索引只能建立函数索引;
5)当被索引的列进行隐式的类型转换时不会使用索引(例:BBQ=2009,而BBQ实际是VARCHAR2,SQL执行时相当于自动执行了TO_CHAR函数);
6)索引列上使用<>(不等于);
2.2.2 优化过滤表达式
在编写程序代码时,我们听说过要讲究良好的编码习惯;其实,编写报表的过滤条件也一样,需要养成良好的编写习惯。理解业务过滤规则后,尽可能用简洁实用的表达式编写。同样的过滤,表达式可以有N种写法,有的简洁明了,直接走索引;有的晦涩难懂,不一定走索引
这里推荐如下优化过滤条件表达式的技巧和注意事项:
1)能用like不用substr(取子串)
2)能用and尽量不要用or
3)尽量不要用 not in、in有条件的情况下,用范围过滤来代替(>,<)
比如上面农发行的例子,过滤就有很多写法,更进一步,我们还可以编写出更简洁的过滤表达式,如: (AC_HB_DUE_BILL_MONTH_YJH5RISK.PROD_CD >= "1") AND (AC_HB_DUE_BILL_MONTH_YJH5RISK a.PROD_CD < "4") 这个过滤效果一样,更简洁,也可以走索引。
2.3 整合共享过滤条件
如果要过滤一个分析表上的某表元的统计范围,我们可以在该表元的过滤条件中设置,也可以在该表元所属维表元的过滤条件设置,甚至还可以在报表的主题集过滤条件中设置;这三处过滤均可达到对一个表元统计范围做限制的目的,但究竟哪个过滤设置更好些呢?
一般来说,报表上的过滤遵循求大的原则;即能放在主题集过滤中的条件就不放在浮动维表元过滤中;能放在浮动维表元的过滤就不放在表元过滤中;这样设置的好处是,过滤条件尽可能公用,避免在每个分析区或每个单元格上逐一编写过滤条件。
因此,在设计一张分析报表前,报表工程师需要对整张分析报表上的各种过滤做到心中有数,从业务上理解透,尽量做好全局统一的整合规划,将报表上所有表元公共的过滤提升到主题集过滤中;同时,在一个分析区内,将多数表元共有的过滤提升到分析区的浮动维表元过滤中去;这样,既可以减轻相同过滤条件的重复编写,同时也让BI分析表sql的where子句生成更清晰。
2.4 优化建模简化过滤
当我们在分析表设计过程中,经常要用到非常复杂的判断逻辑的时候,请一定多思考下,是否可以通过改进建模,简化这些过滤条件?
看看这个过滤条件:
left(N09_B02.DEPT_CLASS,1)="A" or left(N09_B02.DEPT_CLASS,1)="B"or left(N09_B02.DEPT_CLASS,1)="C" or left(N09_B02.DEPT_CLASS,2)="D1" or left(N09_B02.DEPT_CLASS,2)="D2" or left(N09_B02.DEPT_CLASS,2)="D3" or left(N09_B02.DEPT_CLASS,2)="D4" or left(N09_B02.DEPT_CLASS,2)="D5"or left(N09_B02.DEPT_CLASS,1)="E"or left(N09_B02.DEPT_CLASS,1)="F"or left(N09_B02.DEPT_CLASS,1)="G"or left(N09_B02.DEPT_CLASS,1)="H"or left(N09_B02.DEPT_CLASS,1)="J"or left(N09_B02.DEPT_CLASS,1)="K"or left(N09_B02.DEPT_CLASS,1)="L"or left(N09_B02.DEPT_CLASS,1)="M"or left(N09_B02.DEPT_CLASS,2)="N3"or left(N09_B02.DEPT_CLASS,1)="O"or left(N09_B02.DEPT_CLASS,2)="P1" or left(N09_B02.DEPT_CLASS,2)="P9" |
其中DEPT_CLASS是机构类型编码,当编码第一位或头几位满足以上的条件时就是【医疗卫生机构】,才参与统计,可以看到这个过滤很繁琐;如果借助主题建模处理,在主题表或卫生机构通用维表中冗余一个【是否医疗卫生机构】的字段,在数据抽取时预处理好这个字段的值为1或0,那么分析表设计时的过滤条件就简化为is_ylwsjg=1。
3. 设计要素之2--连接模式
3.1 尽量少用连接
主题表间的连接对资源会有很大的消耗,特别是那些主题数据规模较大的分析;因此在报表设计阶段对连接的首要考虑是尽量少的使用主题表间连接。 如何能尽量少的关联主题表呢?这其实是对主题建模提出的高要求,也就是在建模阶段充分理解业务分析需求,将经常需要一起分析、粒度相同的事实合并到同一个主题中;这样经常需要在一起分析的度量和维度都尽可能来自同一个主题,自然就减少了多表间关联的需要。 另外,当某些度量或维度在多张主题上都存在时,我们一定要优先从同一主题上取数,这将带来性能上的大幅提升。
3.2 先分组再连接
前面在理解BI分析表多主题sql时,我们已经探讨过同样是统计两张主题表上的指标,【先分组再连接】相比【先连接再分组】具有很大的性能优势,因此,在报表设计上如果两种模式分析的结果是一样的,那报表工程师都应该想办法优先采用【先分组再连接】的方式设计报表。 报表工程师怎样设计,才能从容地在需要的场景下控制多主题间先分组后连接呢? BI提供了两种途径,一个是遵循【维度一致性原则】,另一个是表元的【连接模式】属性。
3.2.1 维度一致性原则
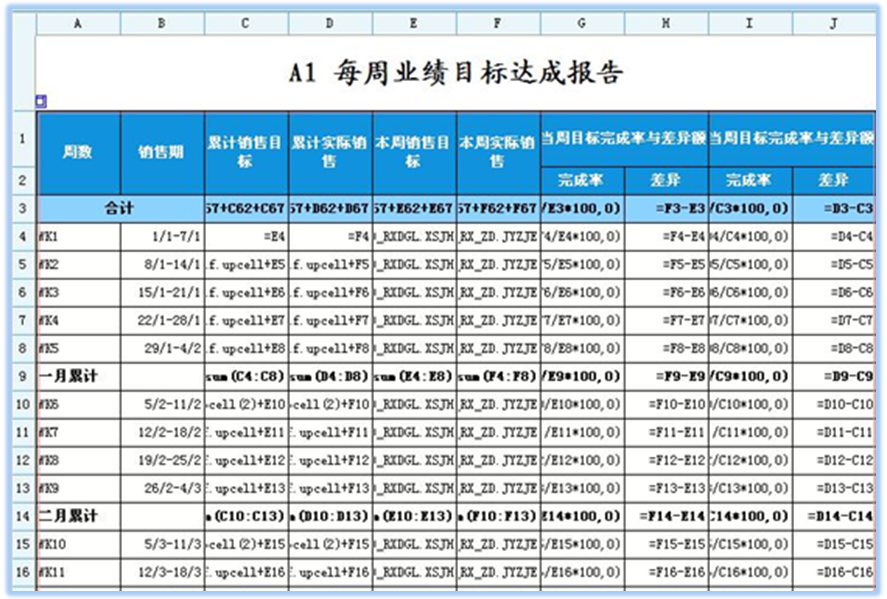
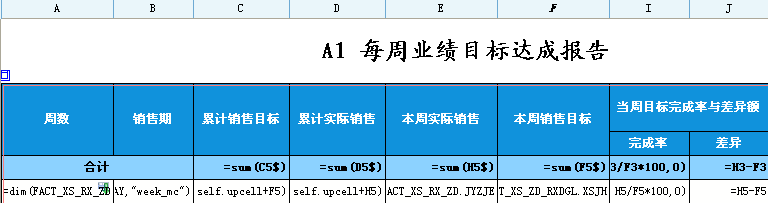
数据仓库理论中的维度一致性原则是指:维度保持一致后,事实就可以保存在各个数据集市中,虽然在物理上是独立的,但在逻辑上由一致性维度使所有的数据集市是联系在一起的。 BI是如何应用维度一致性原则的呢?简单理解就是:在对多张主题按某维度分析时,如果多张主题上都关联了该维度,系统会优先在每个主题中按该维度先分组后,再根据该维度连接多张主题分组后的数据行。 BI在分析表计算时,会自动检测分析报表上的各主题和维表元是否满足【维度一致性原则】,一旦满足,BI自动生成的sql就会尽可能按一致的维度先在各主题中分组后,再按该维度进行多主题分组后数据间的连接。 也就是说,如果报表工程师能确保分析表上引用到的多个主题表,都关联有一致的维度,并且该维度正是当前分析区的分组浮动维,那么就一定能确保这张多主题的分析表sql一定是先分组,后连接的。 让我们看看金利来项目中的这张【每周业绩目标达成】表,如图:

分析表中红方框表元从主题表FACT_XS_RX_ZD(实际销售主题)取出本周实际销售,红椭圆框表元从主题表FACT_XS_ZD_RXDGL(销售目标主题)取出本周销售目标,按照FACT_XS_RX_ZD(实际销售主题)中的DAY字段关联维表的周属性分组。 我们先看看分组的维度是什么? FACT_XS_RX_ZD.DAY:

那销售目标主题上是否关联了该维度呢? FACT_XS_ZD_RXDGL:
 !
!
可以确定,符合一致性维度原则!让我们一起来看看BI是否默契地应用了维度一致性原则,生成的sql是先连接还是先分组?
selectmax(b.week_mc)as B5, sum(a.JYZJE)as E5, b.weekas A5 from FACT_XS_RX_ZD a leftjoin DIM_BBQ_WEEK b on (a.DAY = b.DAY)groupby b.week) a leftjoin (selectsum(a.XSJH)as F5, b.weekas A5 from FACT_XS_ZD_RXDGL a leftjoin DIM_BBQ_WEEK b on (a.DAY = b.DAY) groupby b.week) b on (a.A5 = b.A5) 可以很清晰地看到,是先分组再连接的,太棒了! 不难理解,利用维度一致性原则,能大幅减少表间连接的数据量。另外,如果表与表之间是一对多或者多对多的关系,还能避免数据翻倍翻N番等错误的发生。绝大部分情况,减少表间连接,能提高查询速度,业务逻辑也更清楚。
3.2.2 表元连接模式
有些时候,分析表上多个主题间没有满足【一致性维度原则】,但仍然需要某个主题表和分析区中的主表先分组后再连接,有什么办法调控吗? 有!可以设置表元的【连接模式】属性,如图:

在这个案例中,A2是浮动维表元,浮动区的主表是DJXX(登记信息)主题表,SBXX.HYDM是申报信息主题表中的行业代码,当前表元来自SBXX主题,设置了连接模式为【左连接】;这时,SBXX会先在本表中按HYDM分组后,再和来自DJXX的A2表元连接;这样,报表工程师也达成了报表sql设计为【先分组后连接】的效果。
3.3 一致的连接模式
当两个或多个主题表间需要连接时,尽可能采用一致的连接模式。通常在接到多主题分析需求后,报表工程师需要仔细分析指标间连接关系,尽量能确定一种连接模式应用到所有需要连接的指标上,之后在报表设计时,一定要记得确保配置得一致。切忌在报表设计设置两主题表关联时,几个指标左连接,另外几个内链接,甚至还有些右连接。 在1.3节【为什么多sql】中我们已经探讨过分析表会生成多个子sql的原因,其中之一就是两表间连接模式的不统一,如果原本可以一次连接的两张主题,由于设计的随意,有的设置了左连接,有的没有设置,采用了主题集的默认内连接,结果造成额外多一次的连接开销,该多么地可惜! 另一个推荐使用【一致连接模式】原则的主要原因,是sql执行效率;由于一个sql中多表连接既有left jion又有right join,在某些版本的数据库上执行效率很低,这对sql来说是要尽量避免的,sql的jion方向最好一致。 我们一起来看看江苏卫生厅这个真实的案例: 附图和说明:
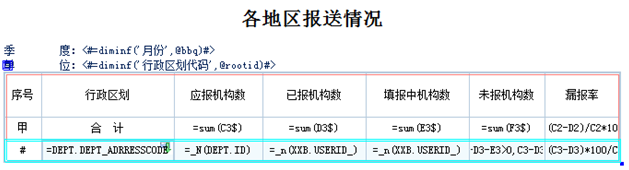
由于主题集中定义了XXB和DEPT两张主题间右连接,而主表和维表的连接是左连接,导致在这张分析表的一个sql中多表连接既有left jion又有right join,在oracle9i上执行效率很低;考虑实际业务场景中XXB和DEPT进行左连接分析结果是一致的,因此将两表连接关系更新为left join,之后速度提升至毫秒级。 详情请参见:
3.4 建模优化连接
连接模式的优化设计,很多要点都再次对主题建模的设计提出了要求;这里我们一并整理如下: 1.为了尽量少用主题表间连接,建模时要充分理解业务分析需求,将需要频繁一起分析且粒度一致的指标和维度设计到一个主题上; 2.为了尽可能遵循一致性维度原则,主题建模时尽可能多地在各主题上冗余一致的维度;
4. 设计要素之3--减少sql个数
4.1 合并分析区
根据1.3【为什么多sql】中的分析,如果一张报表上有多个独立的分析区,BI会为该分析表创建多个独立的sql提交数据库运算。当主题数据量非常大时,每次提交都会消耗不少的资源。
因此,在设计分析区时,报表工程师们不妨更深入的多考虑一点,一定需要独立设置这个分析区吗?可否和其他分析区合并? 如果能合并,多次sql提交变成一次,在大多数环境下,都将会提升报表计算性能。
4.2 能浮动不固定
在BI分析表上,每一个固定维都会生成单独一个sql;而如果多个固定维的效果可以通过一个浮动维+过滤实现,生成的sql将会大大简化,不但读起来清晰,而且执行效率也高。所以一张分析表能用浮动实现就尽量不要做成固定维。 这里有个新案例,参考:
原来用固定报表方式设计,用时长达6分钟,改用设计通用报表期维,按周浮动设计后,仅需25秒,如下图所示:
4.3 表内sum替代sql合计
在分析表上通常都有【合计】行,有时对这个设计元素根据实际需求灵活的变通也可以减少sql的个数。 如下图所示的案例中,几乎每个报表都会有一个汇总统计和时间走势,最初做的报表是两个浮动区域,会产生两条SELECT语句。

分析表截图-1原分析表的上半部分

分析表截图-2原分析表的下半部分
仔细分析发现可以只用一条SELECT语句完成,所需做的改动就是汇总数据不从主题表直接取数,而是根据时间走势的浮动行进行数据的汇总累加,经过这样的修改,大大提高了报表的计算效率。
分析表截图-3改进后分析表的上半部分

分析表截图-4改进后分析表的下半部分
4.4 一致的属性设置
在第1节【理解BI分析表的sql】中我们探讨过,影响sql结构的地方有:表元过滤条件、表元数据期条件、连接模式。来自同一张主题表的指标尽可能保持这3个属性一致,这样他们就能在同一个sql中查询统计。
比如:有3个指标table_a.zb1、 table_a.zb2、 table_a.zb3,在数据源那儿的过滤条件中设置了table_a.hydm="C3400",又在table_a.zb1这个指标的表元上设置了过滤条件table_a.hydm="C3400",这样,table_a.zb1会单独使用一个select查询, table_a.zb2和table_a.zb3用一个select,最后,再把这2个select结果集join起来。 同理还有,2个表元用的是主题集默认连接模式,如内连接,另一个表元是左连接,这样,来自同一个主题表的3个指标也不会在一个select中查询,而是分成2个select然后做连接。
对于一张被多次修改,被多人修改的表,特别容易出现这个问题;这也提醒我们在进行报表设计任务分工时,尽可能同一张报表一个工程师负责到底。
让我们一起看看来自客户的一个报表示例:
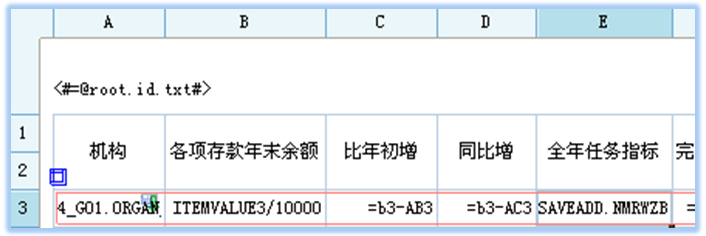
这张表的连接模式为:

客户反馈这张报表计算需要一分半钟,无法忍受!
经分析,我们发现E3和I3、J3、K3、M3、Q3、U3、Y3取自同一张主题表,过滤条件也一样,但是他们却不是在同一个select中求得值的;E3是一个select,后面的I3到Y3是一个select,原因是E3设置了连接模式为左连接,其他的7个都没有设置,使用了主题集的默认连接,不一致;导致执行耗时较长。
4.5 慎用跨表取数
跨表取数虽然可以直接取到已经在别的分析表上设计好的分析结果,但每次取数时,都会触发被取数的分析表再计算一次,其实增加了sql个数,增加了性能负担。
5. 设计要素之4--减轻sql数据量
5.1 多用表内计算
能从表内运算得到的,就不要再从主题表取数,减轻sql数据量压力。
5.2 尽量从数据量少的主题取数
如果同样都可以取到需要的数据,若能从一个数据量更小的主题取数,会大大减轻sql数据量的压力,整体性能自然就可提升。因此,报表工程师在设计分析表时,切不可满足于能取到数,更进一步地稍稍比对下,特别是面对数据量很大的分析需求时,哪个主题数据量更小些?
让我们来看下这个某项目的真实案例:
因为数据量极大,所有分析报表均从聚集表取数,聚集表对明细数据做了多个数据粒度(5分钟、小时、日、月)的聚集,而即便是聚集数据,数据量也很大,有的表在1小时时间范围的5分钟粒度数据就有上百万。
有的报表需要同时显示1小时范围内的汇总统计和时间走势,为了减少SQL查询时间,可以把汇总统计那一块从1小时粒度数据取数,而时间走势则从5分钟粒度数据取数,这样既满足了需求,又提高了效率,只是在做报表的时候,过滤条件要分别写,需要小心和仔细。
5.3 建模数据预处理
5.3.1 物化视图
当查询的数据量特别大的时候,也会导致查询的速度很慢,这个时候,可以先采用物化视图减少数据量,再从这个少的结果集上做查询。 如下所示是卫生的一个实例:
createorreplaceview v_irpt_departments_wt1_5asselect dept_adrresscode,id,isjc,fromdate_,todate_from IRPT_DEPARTMENTS t1minus(select dept_adrresscode,id,isjc,fromdate_,todate_fromIRPT_DEPARTMENTS deptwhere DEPT.ENABLED ="1"AndDEPT.dept_classLike"E%"); 5.3.2 聚集处理
如果项目中有不少分析无需在明细粒度的主题上进行,并且数据量特别大,可以对基础数据做某些维度上的聚集,这样可以大大减少sql数据量。
6. 其他设计
6.1 量大就分页
有些时候我们发现数据库sql早就执行完毕,可分析表迟迟刷新不出来,这是什么原因呢?原来,如果页面数据行数太多,浏览器的刷新显示会非常缓慢,严重情况下,还会导致浏览器挂掉。
所以,遇到结果行数多的时候,尽量让分析表进行分页。此时,如果用表内求和计算了合计行,就要注意了,分页后的表内计算只会对当前页的数据求和。如果需要对所有数据行求和,请从数据库对指标求sum,而不是对分析表上的某个浮动表元求sum。
6.2 巧用报表参数
在钻取的分析场景中,如果子表要引用主表的数据,用参数传递、用sql数据源、用跨表取数,都可以达成需要的效果;但采用参数传递的方案,是最优的;道理很简单,参数传递方案使用的是计算好的值,而其他方案都需要再计算。
6.3 少隐藏,多合并
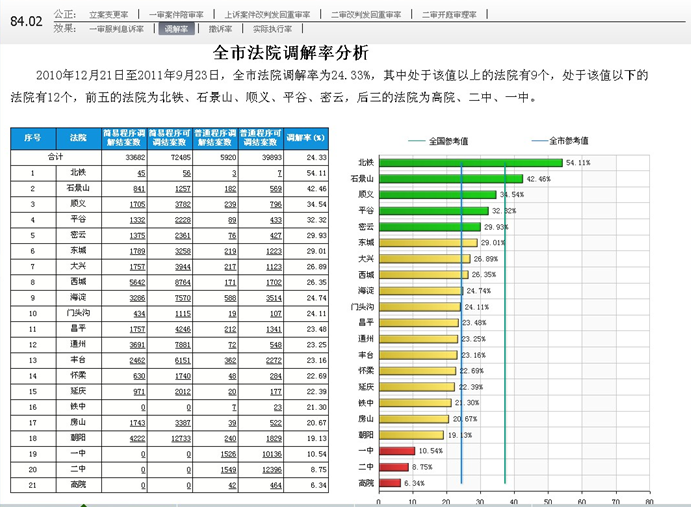
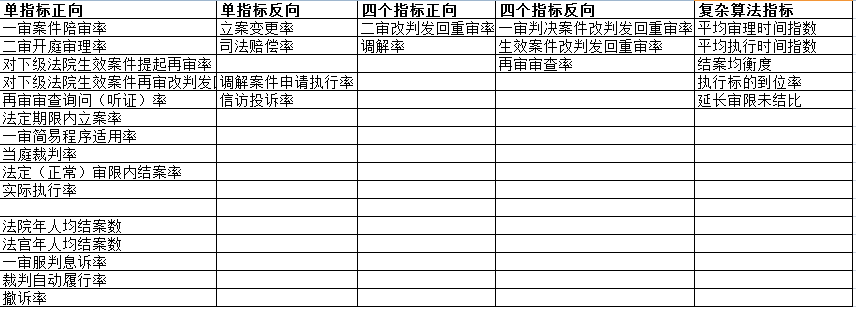
如上图,司法效能一共有28个指标,这28的展示方式基本相同,都是序号、法院、分子、分母、率的模式,报表中有个"分析指标"的参数,我们需要根据用户选择的指标,进行分析和统计。
如果不考虑性能,最直接的做法,就是将28个指标做到一张分析表上,再设置列隐藏,用户选择统计哪个指标,再把相应的列显示打开。这确实是一种很直白的做法,但是性能却不太好,用户需要统计的只是其中的一个指标,而系统每次都需要计算28个,想想都觉得BI辛苦啊!
遇到这种需求,建议先不忙动手,先分析这些指标的算法,做好分类。
已知指标分方向分为正向和逆向,计算公式也分成三类,一类单个指标相除即可得到;一类需要多个指标相除后再加减才能得到;还有一类是需要用特殊的算子或公式才能算的。总结下来,28个指标,我们做5类报表就能够解决问题。
建议用"IF+报表参数"来实现。定义表达式时用if嵌套,根据参数的值,决定取哪个字段以及如何计算。
不推荐"参数+隐藏列"来实现。
小结
读到这里,你的脑袋瓜可能已经很满了。你可能会无限期待地说"要是这些原则这些注意事项BI都能自动处理该多好啊"!
是的,BI的蓝图正是这么规划的,BI也一直在努力。达成这个愿景还需要比较长的一段时间,在这个过程中,需要我们所有报表工程师们更深入的懂BI,帮助BI回避那些会让BI无法优化的设计方式,在BI目前还没能智能优化的点上再多优化一些,或者创造先天条件让BI可以更好的优化。而这些仅仅只需要我们在设计报表时,稍微抬下头,休息下眼睛,思考小会。
我们建议报表工程师在设计分析表时总是尽量按优化的原则来做;一是形成良好的设计习惯,这些习惯一定会给你不小的性能优化回报;二是如果等到系统数据量增大后,再发现报表必须做很多优化,则将带来巨大的报表修改和测试工作量;第三,在很多情况下,不好的报表设计所造成的性能问题是数据库优化也无法解决的(如同在WHERE条件列上作函数操作,除了建代价相当大的函数索引外,数据库层面别无他法,而修改过滤条件却是轻而易举的事情),因此报表工程师需要从报表设计角度未雨绸缪。


请先登录