1.概述
采集数据库的元数据时,既可以使用各数据库自己的采集适配器进行采集,也可以使用JDBC采集适配器进行采集,且JDBC采集适配器支持设置采集范围,包括设置采集的元数据类型以及元数据范围。
2.配置说明
2.1采集数据源配置
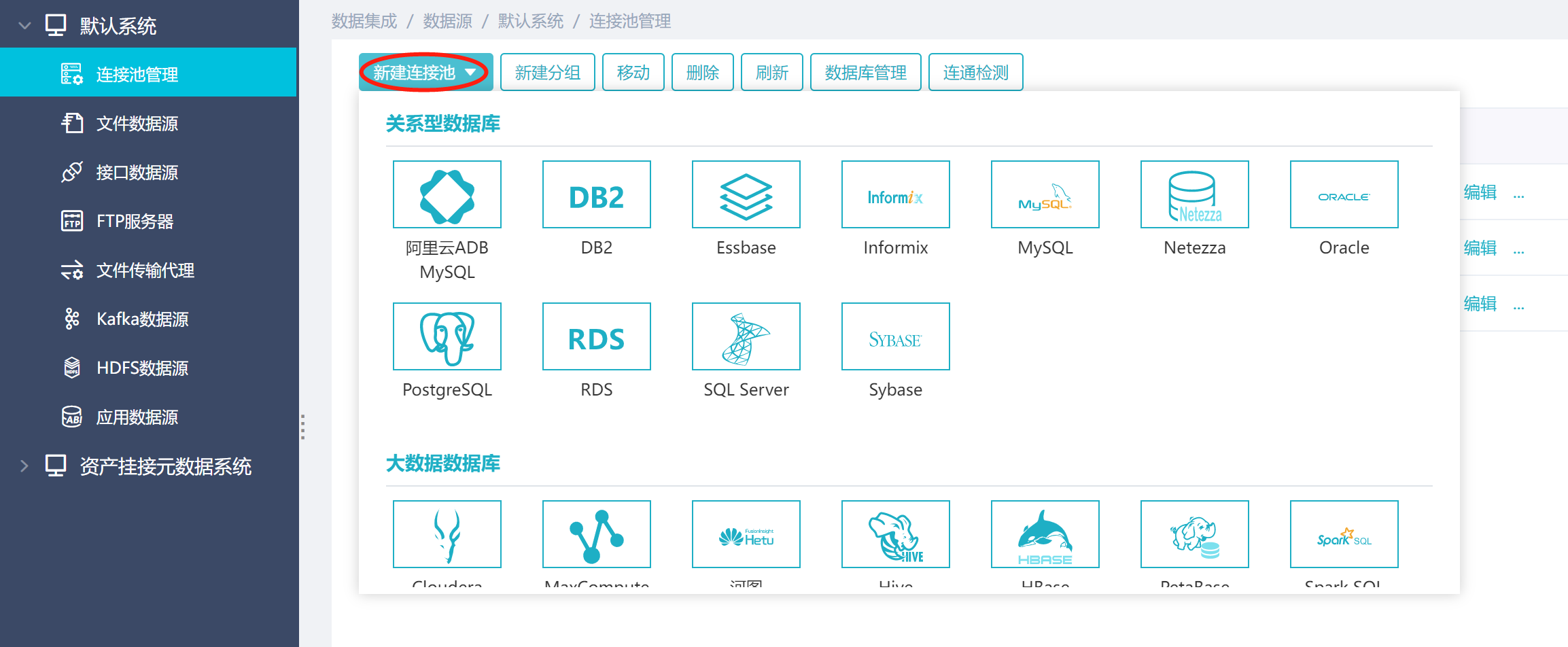
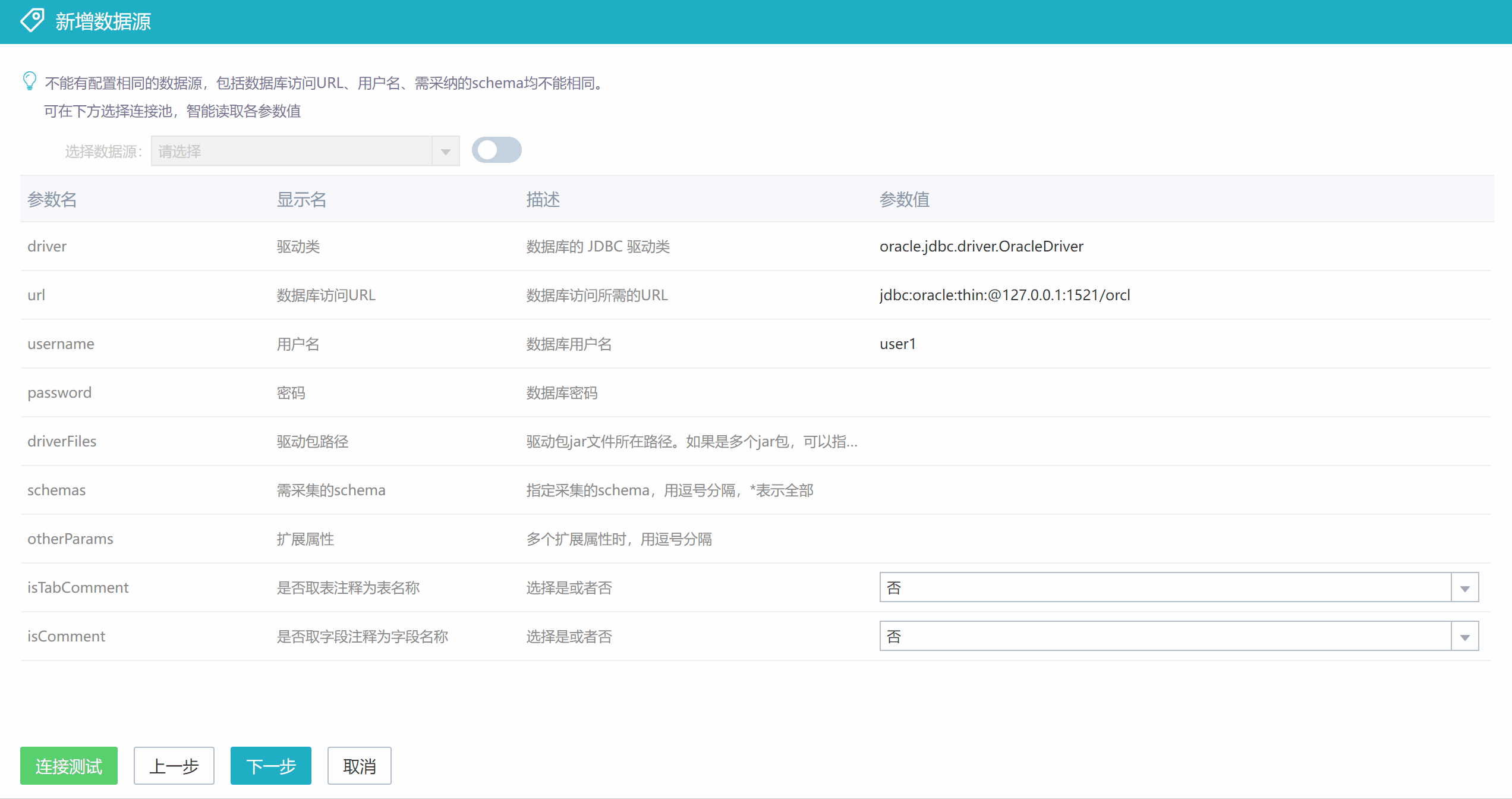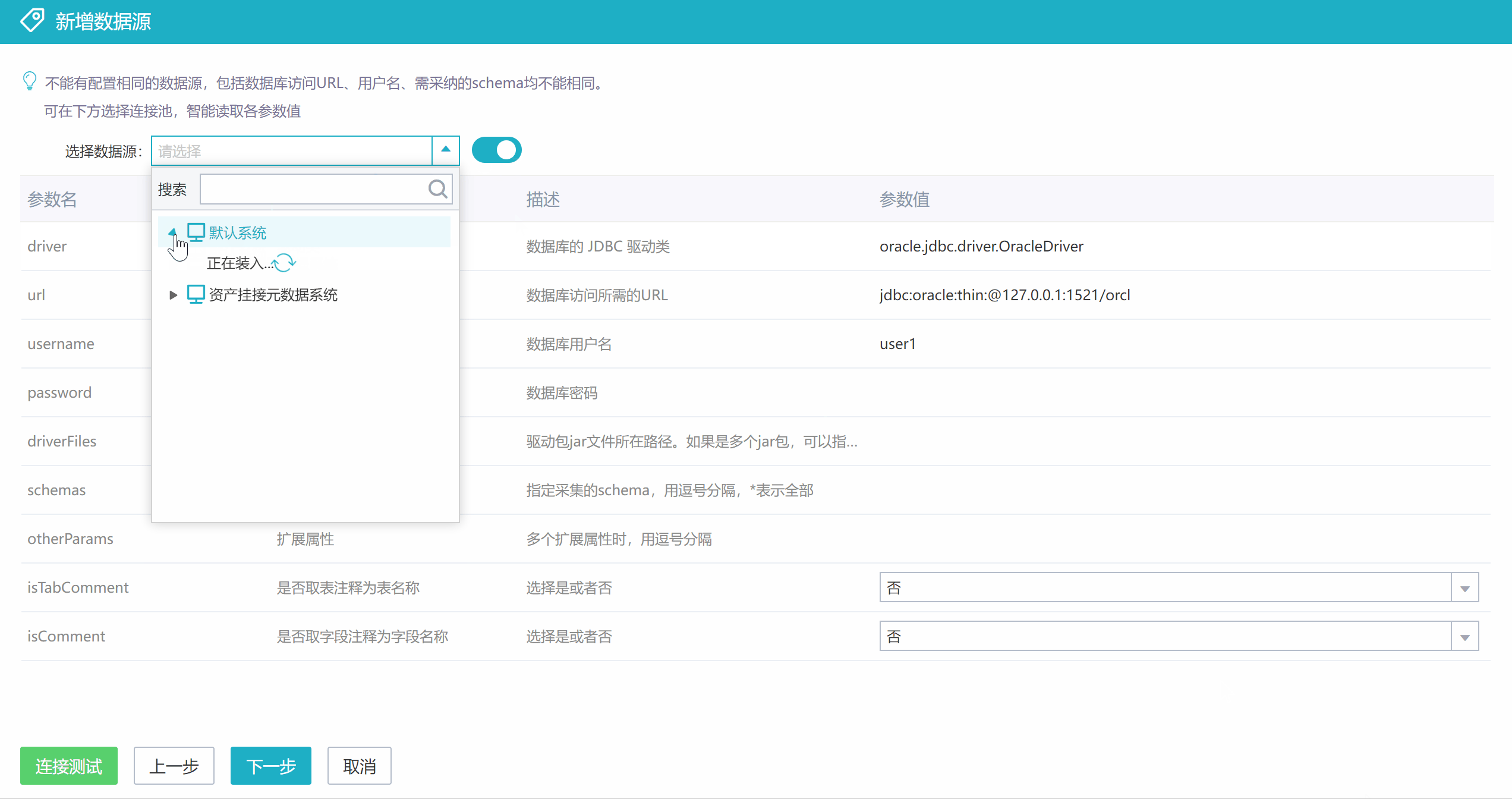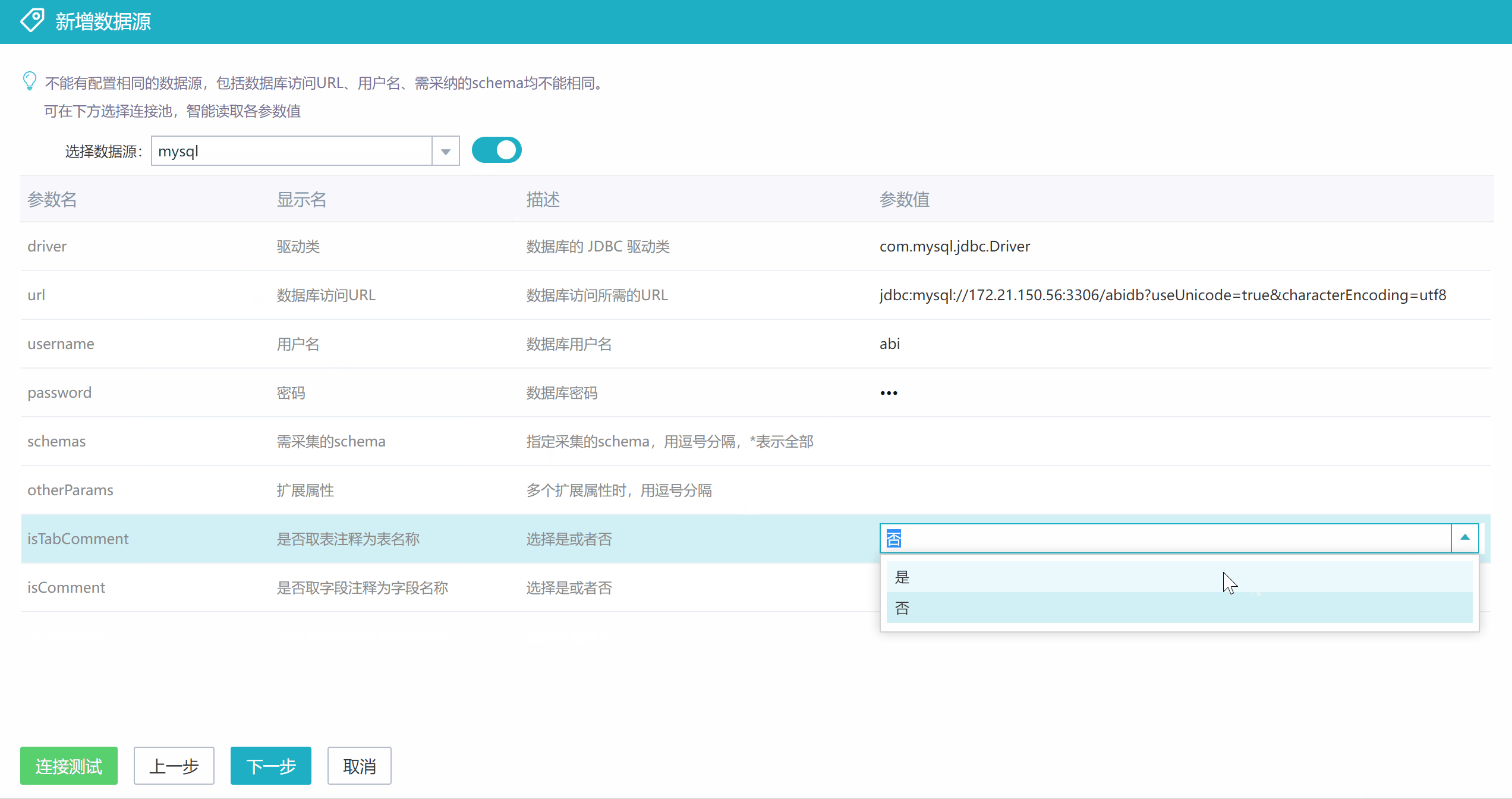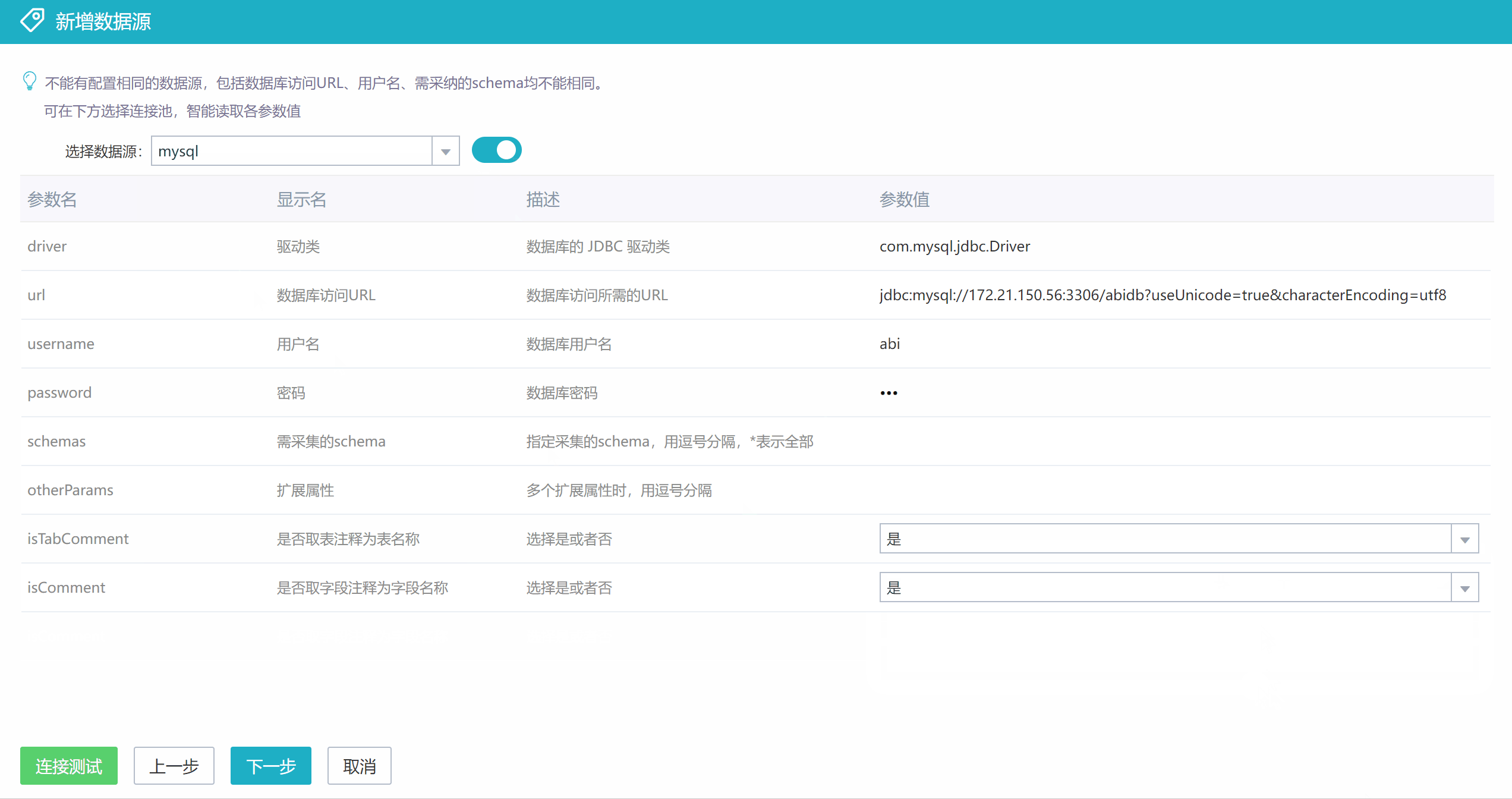
1)方式一
根据实际需求进行数据源配置。比如下图为采集某个oracle数据库的数据源配置,schemas参数设置的是wlf3,表示采集wlf3这个数据库用户下的元数据。

驱动类(driver)和数据库访问URL(url)默认给的是oracle数据库的配置示例,如果是采集其他类型数据库,需要进行相应修改。这里支持的数据库类型以及driver和url示例见下面表格:
类型 | 数据库 | driver | url |
关系型数据库 | Oracle | oracle.jdbc.driver.OracleDriver | jdbc:oracle:thin:@127.0.0.1:1521/servicename |
Mysql | com.mysql.jdbc.Driver | jdbc:mysql://127.0.0.1:3306/dbname?useUnicode=true&characterEncoding=utf8 | |
DB2 | com.ibm.db2.jcc.DB2Driver | jdbc:db2://127.0.0.1:50000/dbname | |
SQLServer | com.microsoft.sqlserver.jdbc.SQLServerDriver | jdbc:sqlserver://127.0.0.1:1433;databaseName=dbname; | |
Sybase ASE | com.sybase.jdbc3.jdbc.SybDriver | jdbc:sybase:Tds:127.0.0.1:5000/dbname?charset=cp936 | |
PostgreSQL | org.postgresql.Driver | jdbc:postgresql://127.0.0.1:5432/dbname | |
Greenplum | com.pivotal.jdbc.GreenplumDriver | jdbc:pivotal:greenplum://127.0.0.1:5432;DatabaseName=dbname | |
Informix | com.informix.jdbc.IfxDriver | jdbc:informix-sqli://172.0.0.1:9088/dbname:INFORMIXSERVER=ifxserver;NEWCODESET=GBK,8859-1,819,Big5;NEWLOCALE=en_us,zh_cn; | |
国产数据库 | ArteryBase | com.thunisoft.ArteryBase.Driver | jdbc:ArteryBase://127.0.0.1:5432/test?Charset=utf8 |
Gbase | com.gbase.jdbc.Driver | jdbc:gbase://172.21.10.98:5258/test_gbase | |
Huawei-elk | org.postgresql.Driver | jdbc:postgresql://127.0.0.1:25108/dbname?currentSchema=public | |
KingBase8 | com.kingbase8.Driver | jdbc:kingbase8://127.0.0.1:54321/dbname | |
LinkoopDB | com.datapps.linkoopdb.jdbc.JdbcDriver | jdbc:linkoopdb:tcp://127.0.0.1:9105/db_name | |
MaxCompute | com.aliyun.odps.jdbc.OdpsDriver | jdbc:odps:http://service.cn-beijing.maxcompute.aliyun.com/api?project=ODM | |
PetaBase2.1 | com.esen.jdbc.PetaBaseDriver | jdbc:petabase://127.0.0.1:21050/dbname;auth=noSasl | |
星环Transwarp | org.apache.hive.jdbc.HiveDriver | jdbc:hive2://127.0.0.1:10000/default | |
达梦数据库 | dm.jdbc.driver.DmDriver | jdbc:dm://127.0.0.1:5236 | |
大数据库 | Hive | org.apache.hive.jdbc.HiveDriver | jdbc:hive2://127.0.0.1:10000/default |
Vertica | com.vertica.jdbc.Driver | jdbc:vertica://172.21.10.19:5433/testdb |
2)方式二
也可以先在【数据集成】-【数据源】中创建一个指向待采集数据库的连接池(这里选择相应的数据库类型可以自动带出驱动类和url示例)。

然后在采集数据源配置这里选择上面建好的连接池,会直接带出驱动类、url、用户名和密码等设置,再补充其他参数值的设置。
下一步,进入采集类型配置。
2.2采集类型配置
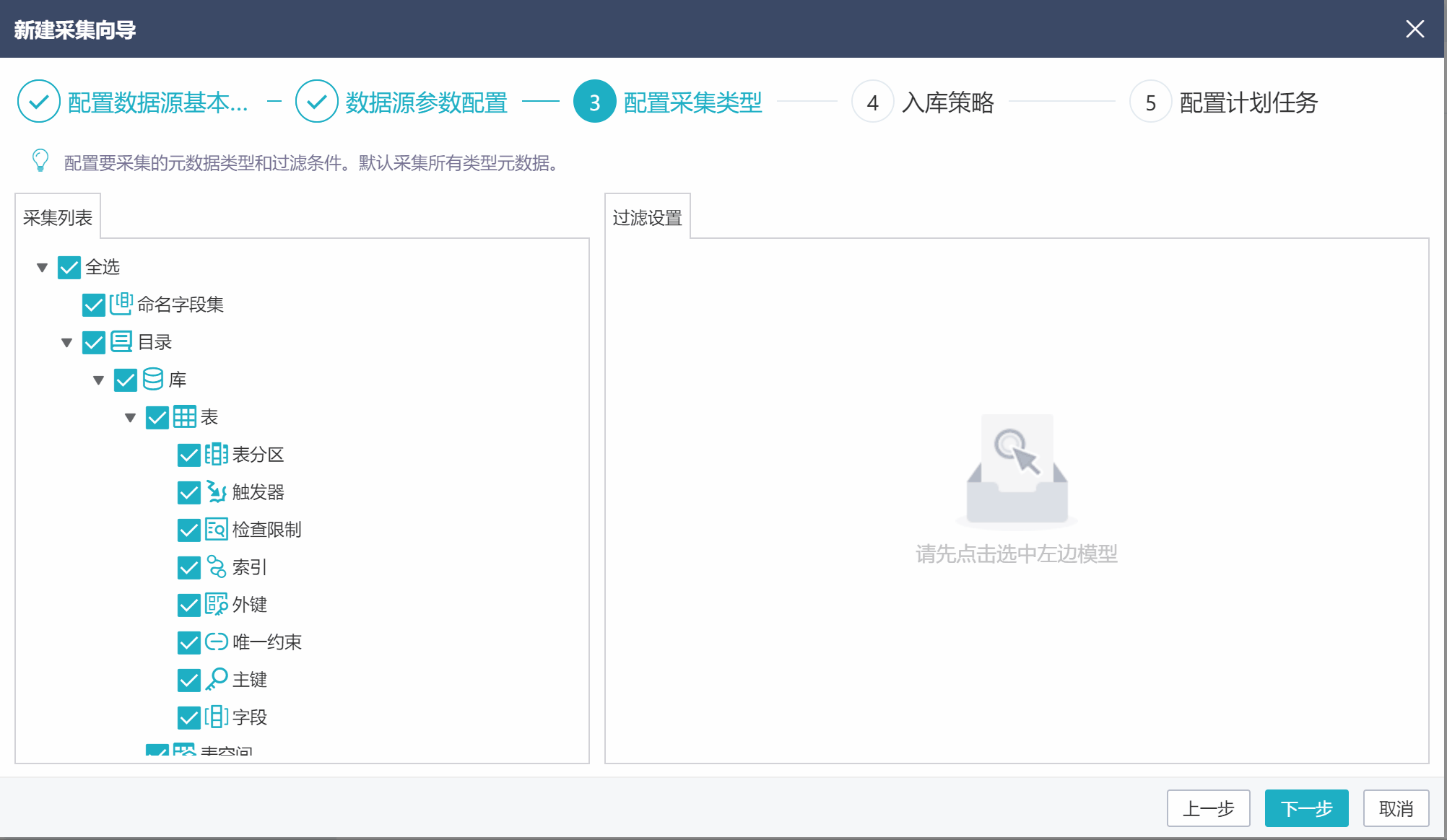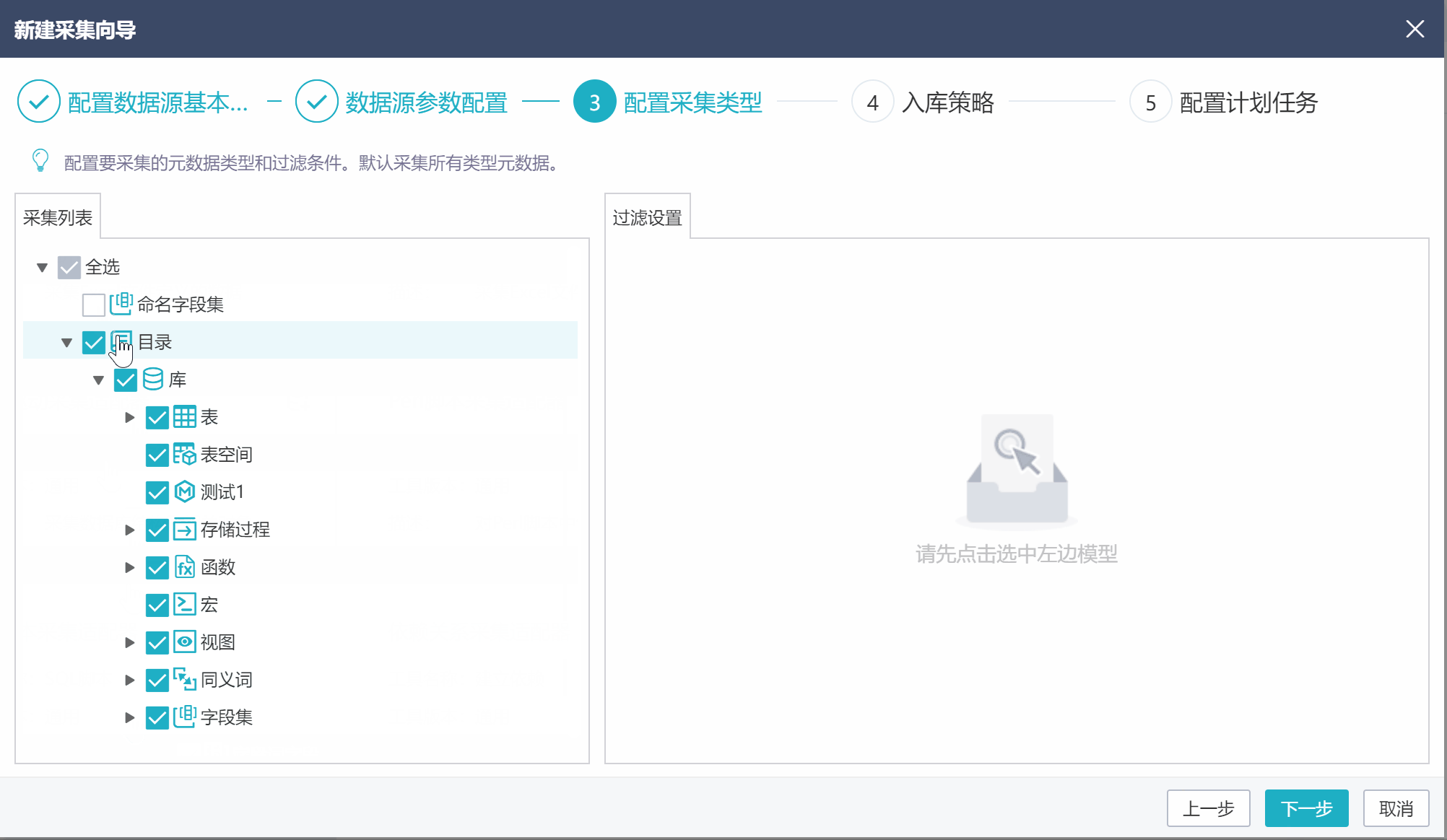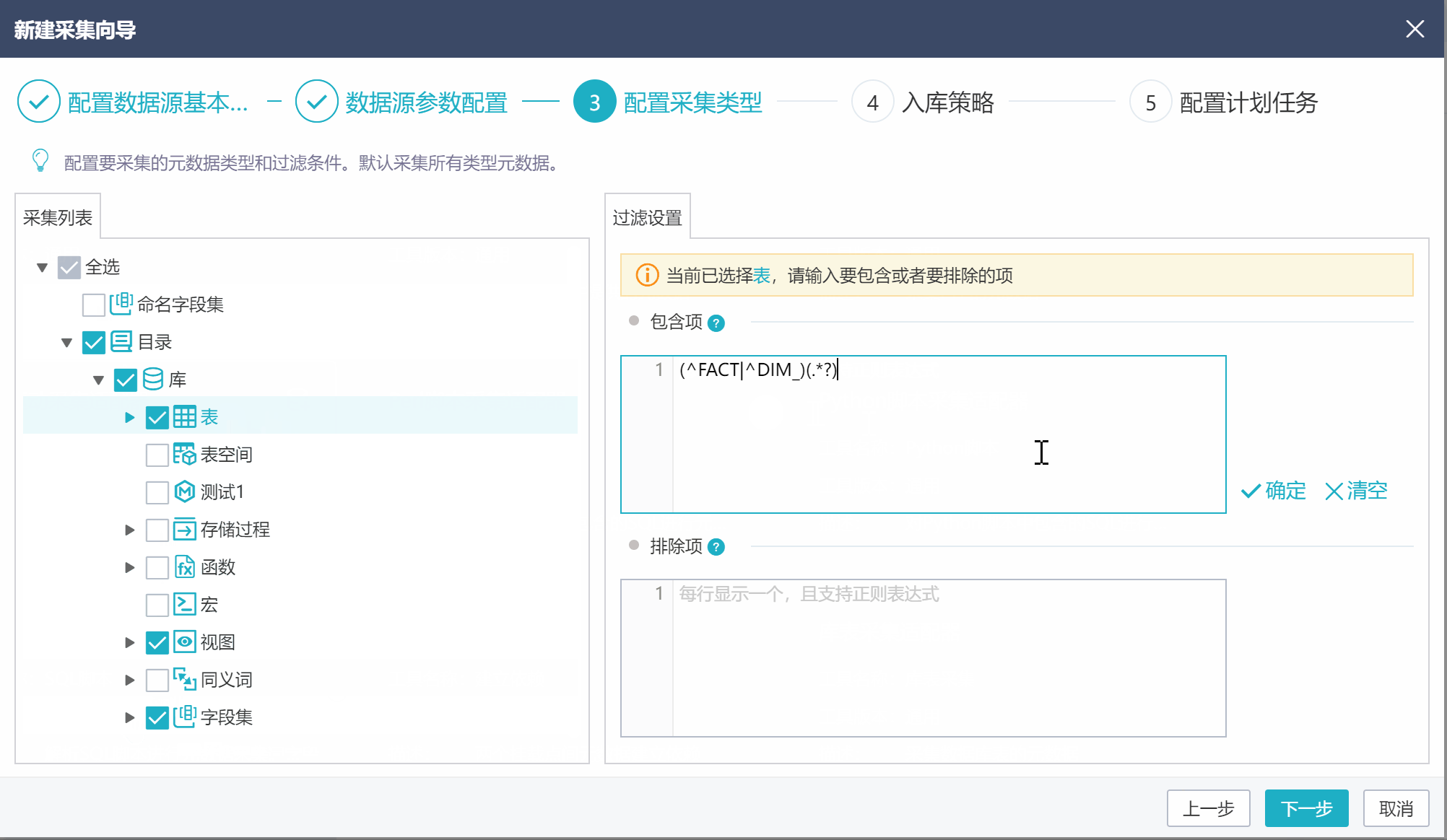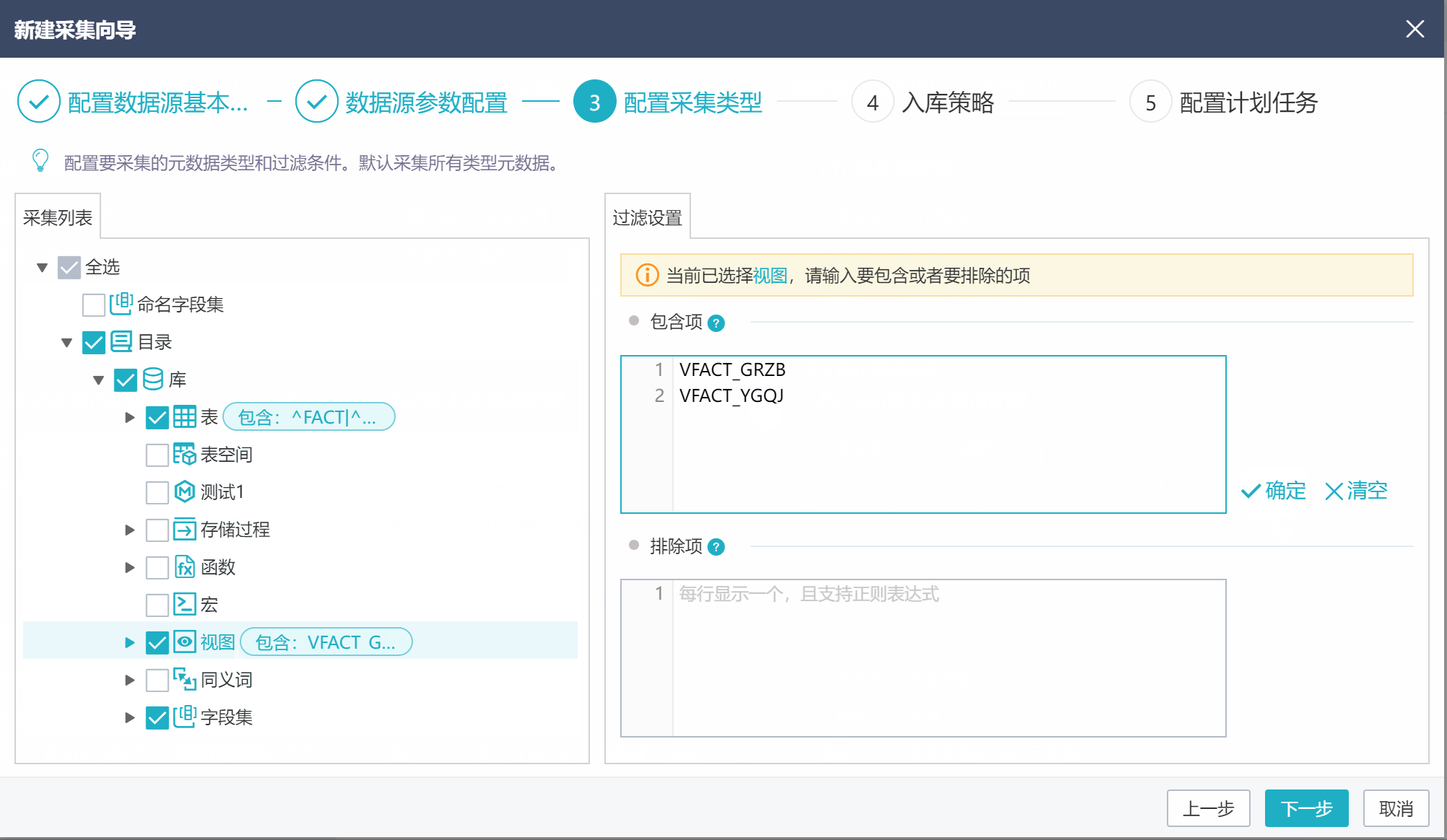
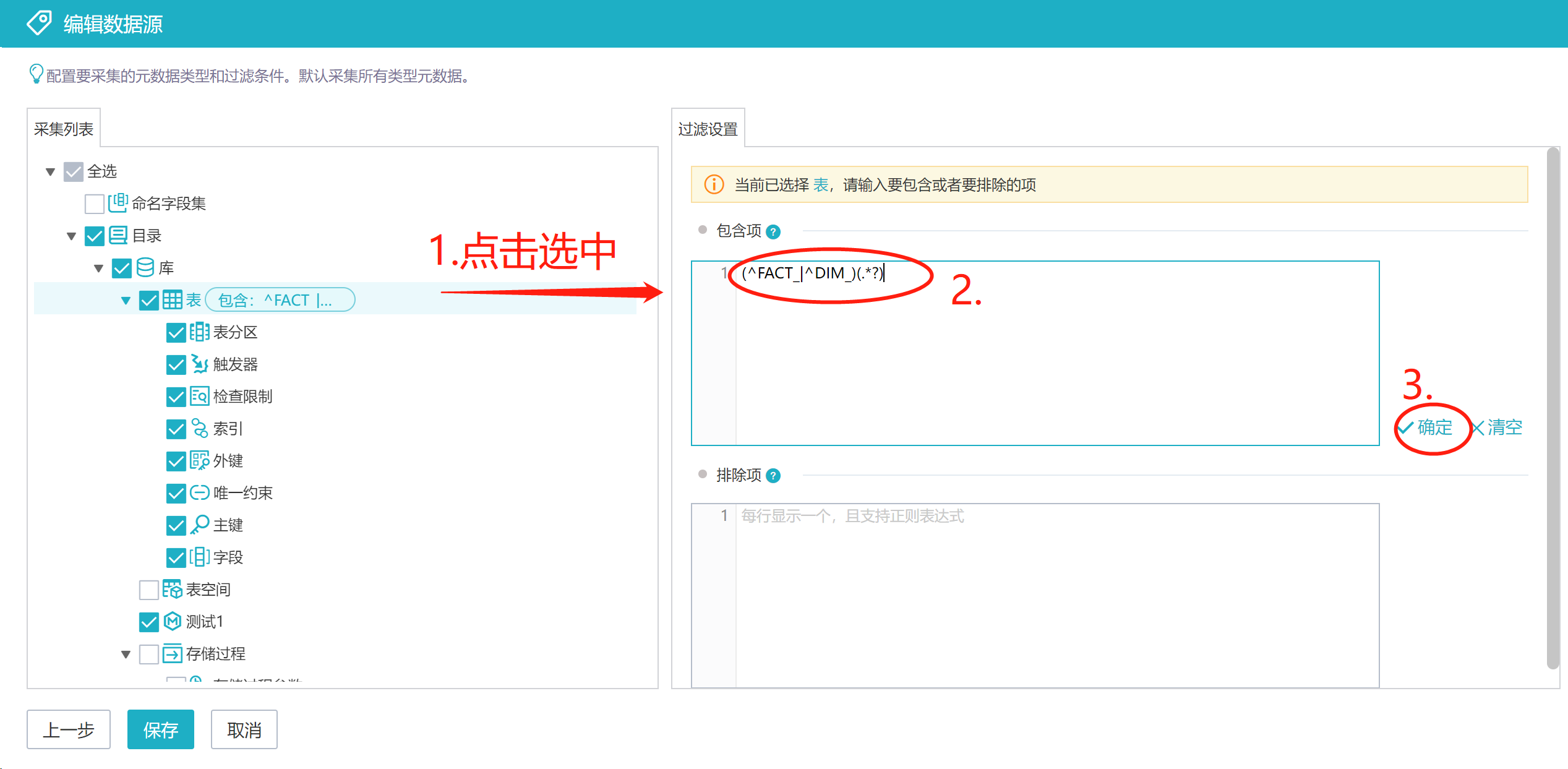
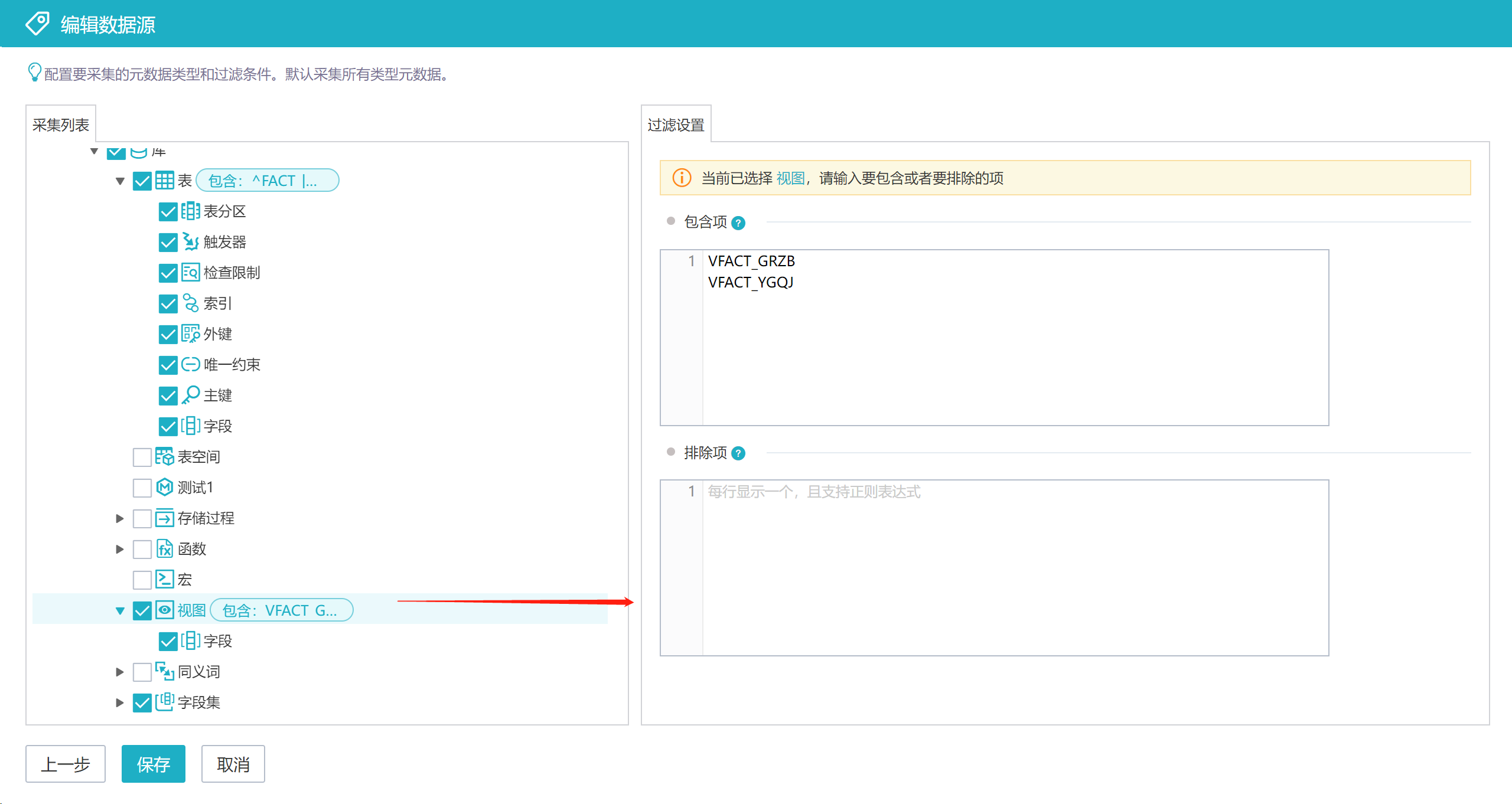
在采集类型配置界面,可设置采集的元数据类型,以及每类元数据的采集范围。比如,只采集表和视图,以及他们的组合项(字段、索引等),且表只采集以DIM_和FACT_开头的表,视图只采集VFACT_GRZB和VFACT_YGQJ。具体设置如下图。
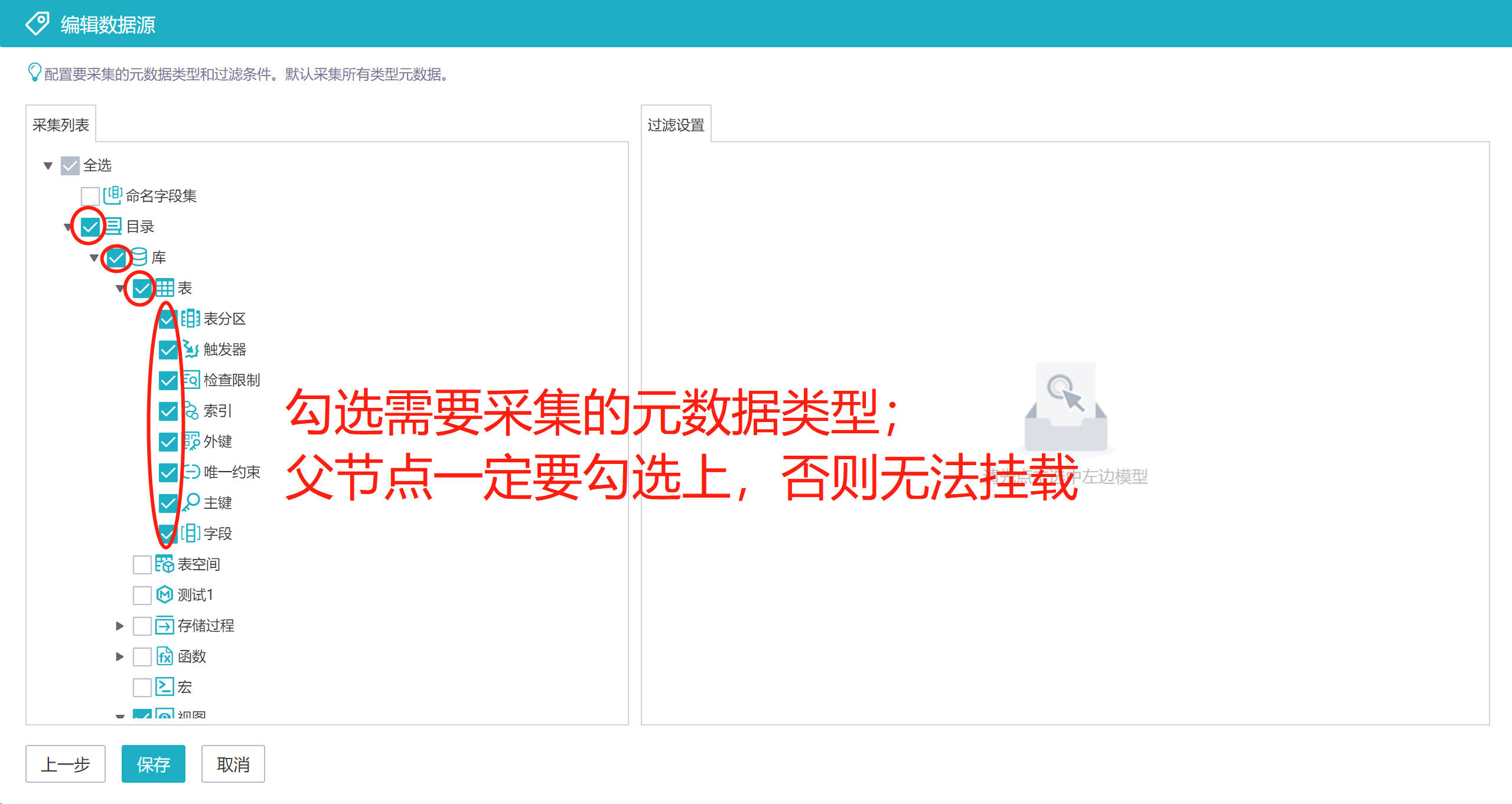
注:表、视图和字段集下都有字段,他们都是同一种元模型——字段元模型。不能精确到比如只采集表的字段,不采集字段集的字段。只能字段要么采集,要么不采集。故这里不能去掉字段集的勾选。
可以看到,左侧的采集列表用于勾选需要采集的元数据类型,默认都是勾选的。
点击选中采集列表中的元数据节点,右侧页面用于设置这类元数据的采集范围。【包含项】是要采集的元数据,不设置代表采集全部;【排除项】是不采集的元数据,不设置代表无。


请先登录