1.边缘采集输入输出组件
本章节主要介绍了如何使用边缘采集输入输出组件实时采集服务器上的日志数据。
前提条件
1、需要提前在采集服务器上安装边缘节点程序。
2、在使用边缘采集输入输出组件前,需要配置边缘节点的IP地址和端口号。
应用场景
story:客户需要采集tomcat服务器实时产生的日志数据,并实时解析入库;为实时平台操作分析提供数据支撑。
操作步骤
1、边缘采集输入输出组件主要是实现了基于服务器应用日志进行实时更新,实时监听服务器的日志数据,当日志数据中有新增后,将新增的数据输出至内存区进行缓存,然后输出到目标中。系统操作流程如下:
操作入口:任务管理-新建实时任务-实时任务设计器
目前边缘采集输入组件支持以下五种
(1)边缘采集Avro输入组件:可通过RPC接收Avro数据,将数据输入到内存中。
(2)边缘采集文件目录输入组件:可监听目录下的新文件,将数据输入到内存中,不支持断点续传。
(3)边缘采集Kafka输入组件:可从Kafka中读取数据,将数据输入到内存中。
(4)边缘采集文本输入组件:可监听目录或文件,将数据输入到内存中,支持断点续传。
(5)边缘采集Http输入组件:可接收外部HTTP客户端发送过来的数据,将数据输入到内存中。
边缘采集输出组件支持以下四种
(1)边缘采集HDFS输出组件:可从内存中接收FLUME编译器输入组件的数据,将数据通过RPC实现端到端的批量压缩数据传输。
(2)边缘采集Avro输出组件:可从内存中接收FLUME编译器输入组件的数据,将数据写入HDFS文件系统。
(3)边缘采集HBase输出组件:可从内存中接收FLUME编译器输入组件的数据,将数据写入Hbase时序数据库中。
(4)边缘采集Kafka输出组件:可从内存中接收FLUME编译器输入组件的数据,将数据写入Kafka指定主题中。
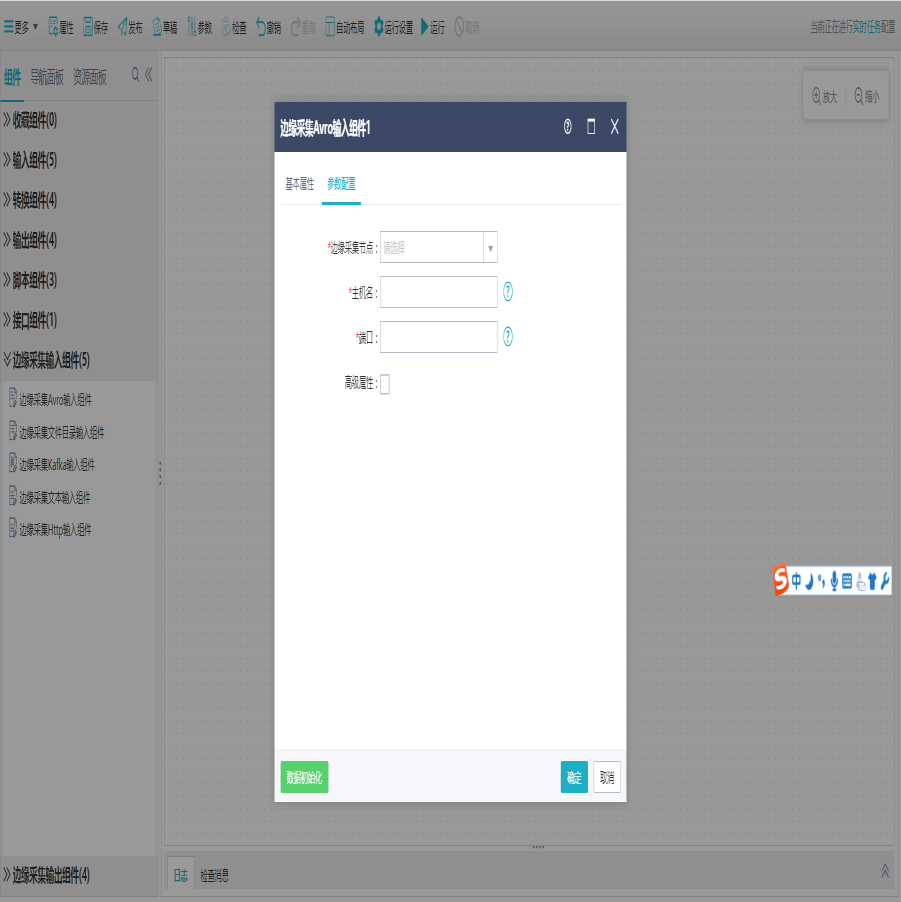
①在ETL任务设计器分组“边缘采集输入组件”下拖出“边缘采集Avro输入组件”。双击该组件,配置采集的边缘节点、输入源的具体信息。
a.边缘节点(默认使用内存方式缓存数据):选择边缘节点,系统根据配置的边缘节点程序,采集服务器上实时产生的日志数据。
b.主机名:监听主机名/IP
c.端口:绑定监听端口,该端口需未被占用
d:高级属性:扩展属性用来配置非必填项的其他属性,格式为:key=value。
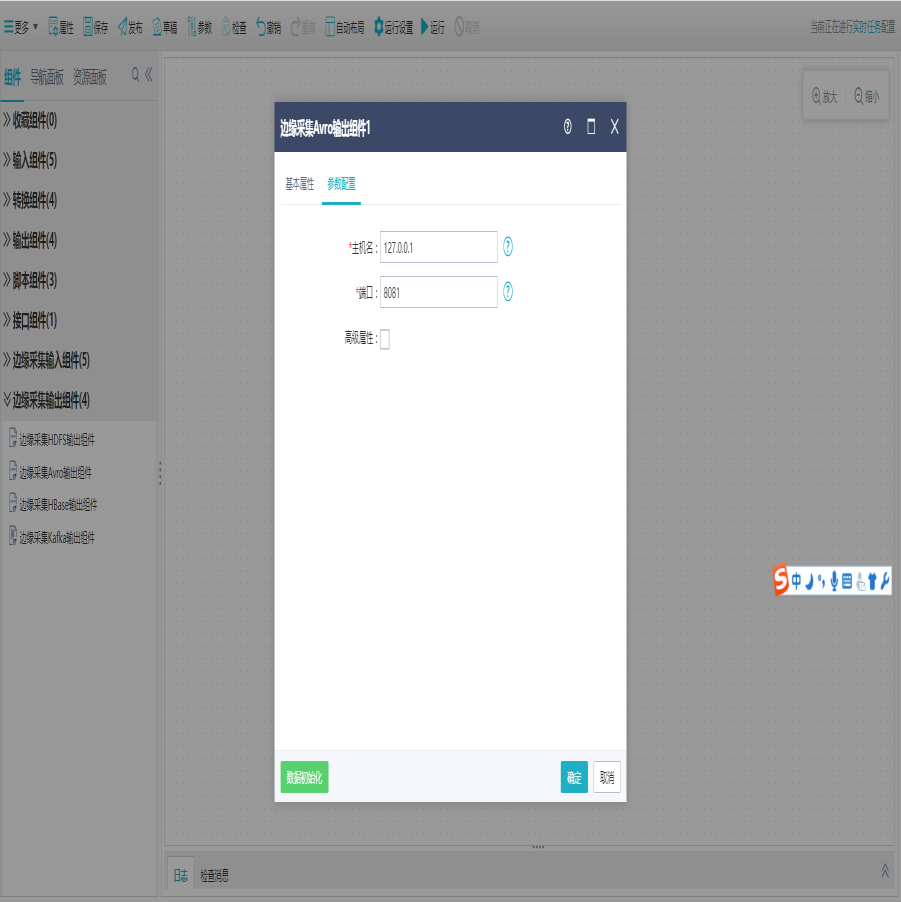
②在ETL任务设计器分组“边缘采集输出组件”下拖出“边缘采集Avro输出组件”。,将之前配置好的“边缘采集Avro输入组件”连接此组件,然后双击“边缘采集Avro输出组件”,配置数据的输出目标信息。
a.主机名:绑定的主机名/IP
b.端口:监听端口
c:高级属性:扩展属性用来配置非必填项的其他属性,格式为:key=value。
③点击【运行】,系统跟据配置的边缘节点程序,即可实现实时采集服务器上产生的日志数据。
注:
1、实时任务点击【运行】后,默认在后台一直运行,直到用户点击【取消】后才会终止。
2、采集组件和推送组件支持多对多的连线。
2.脚本组件-实时
2.1实时Groovy脚本组件
本章节主要介绍了如何利用用户在Java脚本中调用数据挖掘环境中的算法包进行数据挖掘获得结果数据。
前提条件
用户是技术人员,对Java编程非常擅长,通过脚本组件可以直接支持写Java代码进行数据处理。
应用场景
目前在大数据处理这块,开源Hadoop很多组件提供了各种语言进行数据处理程序开发,一些大数据组件如SparkSQL也提供了基于SQL的方式进行数据查询处理方法,不同技术人员会使用不同的方式进行大数据处理。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>脚本组件-实时Groovy脚本】
1)新建实时Groovy脚本组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择实时Groovy脚本组件拖拽到右边编辑区域。
双击Groovy脚本组件,打开设置界面,编写实时Groovy脚本。
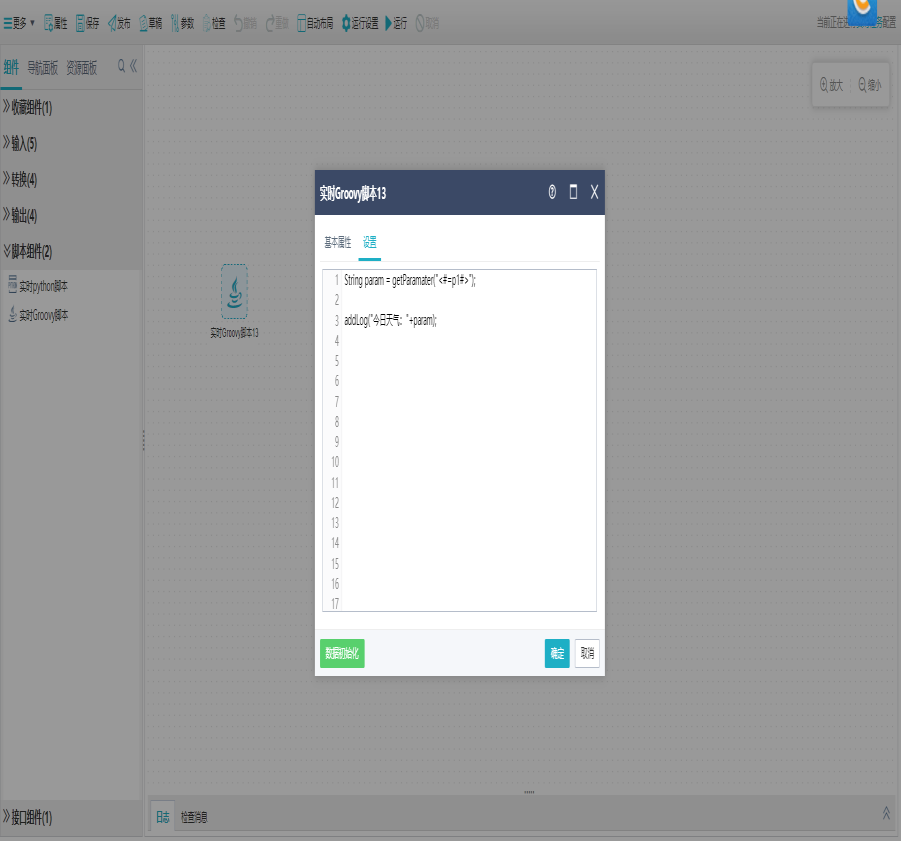
注:提供脚本方式直接支持编写Java;本次版本仅支持Java。
2.2实时Python脚本组件
本章节主要介绍了如何利用用户在Python脚本中调用数据挖掘环境中的算法包进行数据挖掘获得结果数据。
前提条件
用户是技术人员,对Python编程非常擅长,通过脚本组件可以直接支持写Python代码进行数据处理。
应用场景
目前在大数据处理这块,开源Hadoop很多组件提供了各种语言进行数据处理程序开发,一些大数据组件如SparkSQL也提供了基于SQL的方式进行数据查询处理方法,不同技术人员会使用不同的方式进行大数据处理。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>脚本组件-实时Python脚本】
1)新建实时Python脚本组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择实时Python脚本组件拖拽到右边编辑区域。
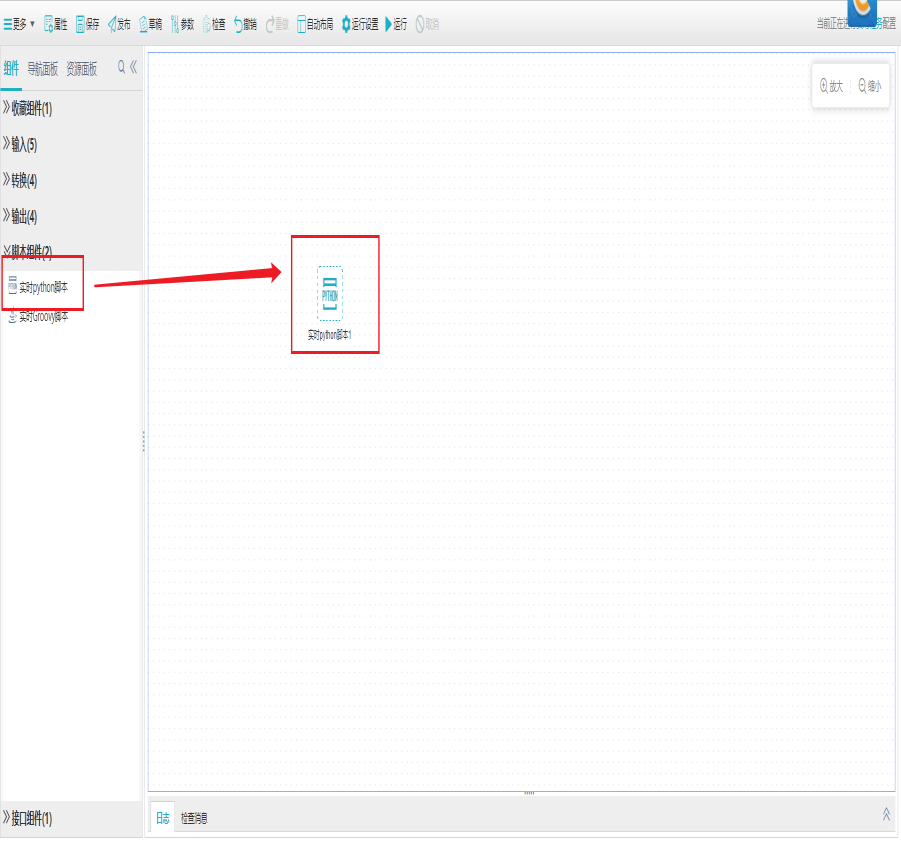
2)界面设置
双击Python脚本组件,打开设置界面,设置运行模式、输出类型。
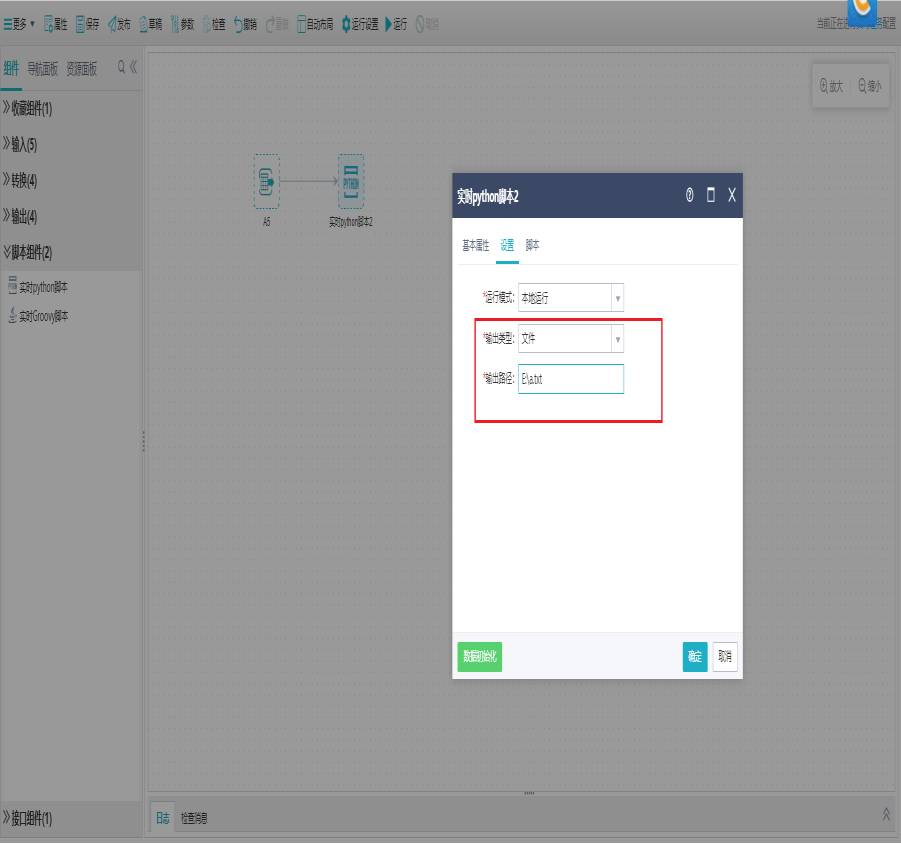
注:输出类型为文件的时候,可以脚本执行的结果写入到指定的文件中。
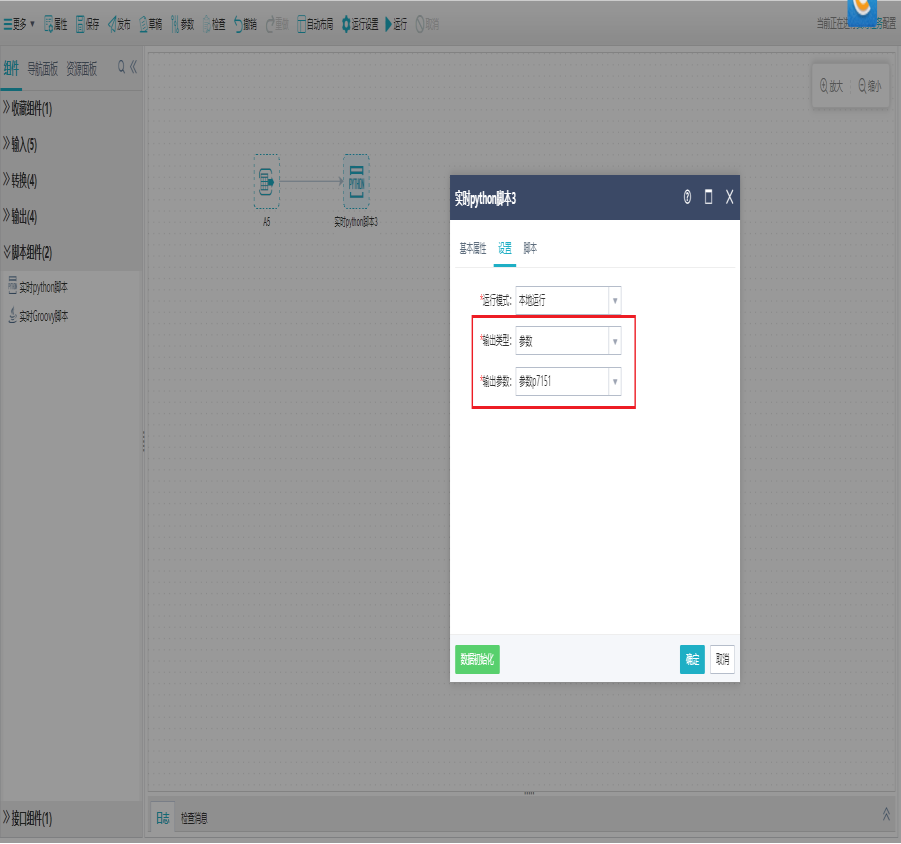
注:当这个输出类型为参数的时候,可以把脚本执行的结果当作参数值赋值给定义的全局参数。输出类型为无的时候就不会有返回值了。
切换到脚本界面,编写实时Python脚本。
3.接口组件-实时
3.1实时Json解析组件
本章节主要介绍了如何利用实时JSON解析组件将一个JSON解析成数据库表。
前提条件
用户已部署相应服务器。
应用场景
实时json解析组件可以从前置实时组件中读取到json格式的数据,然后将其解析成结构化数据,并向后置组件输出。
客户的一个接口返回的用户信息,姓名性别身份证家庭住址等等,这些信息是以JSON的形式返回的,可以通过时JSON解析组件将用户的信息落地到数据库表。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>接口组件-实时JSON解析】
1)新建实时JSON解析组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择实时JSON解析组件拖拽到右边编辑区域。
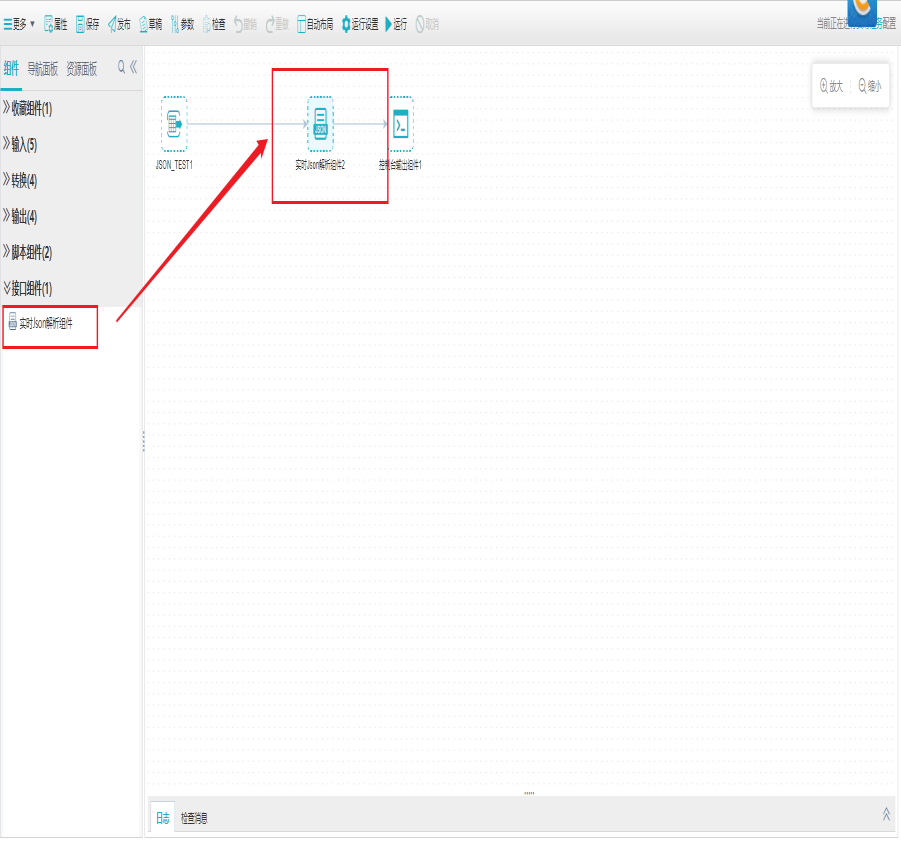
双击JSON解析组件,打开JSON设置界面,选择字段、父级属性名、解析节点类型。

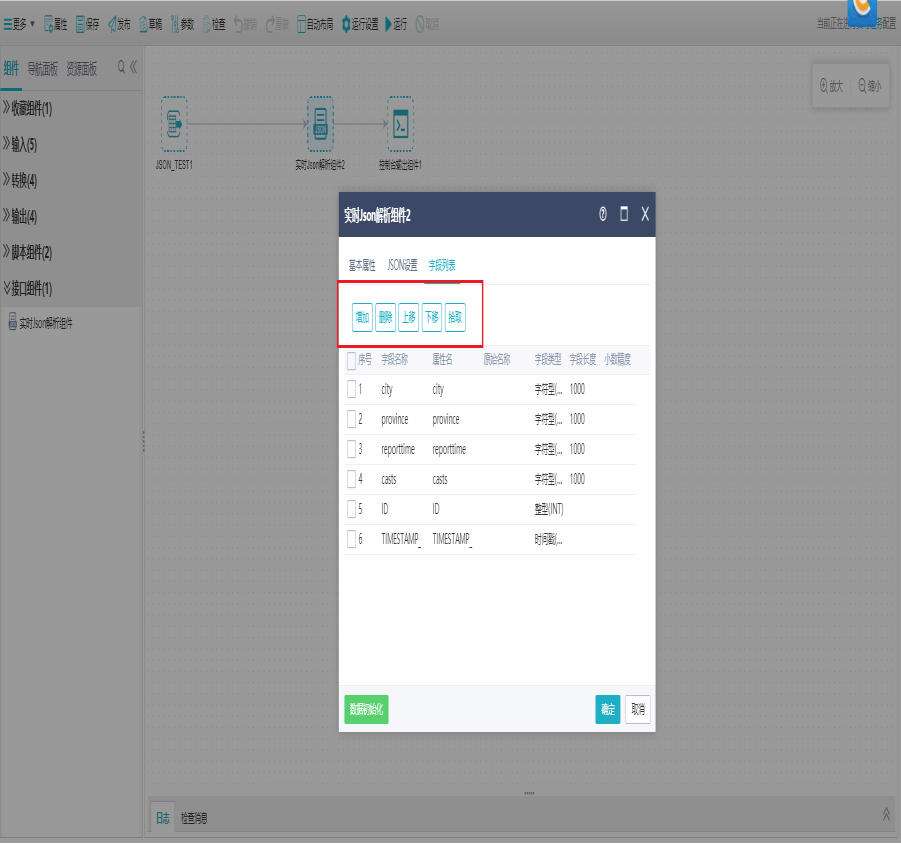
切换到字段列表界面,对字段进行拾取、增加、删除、上移、下移,点击确定。
4.输出组件
4.1Kafka生产组件
本章节主要介绍了如何利用Kafka组件实现对消息写入Kafka集群中。
前提条件
用户已部署Kafka服务器。
应用场景
Kafka是一种高吞吐量的分布式发布订阅消息系统,Kafka发布环节由生产者进行消息采集和发布。
在数据源中配置Kafka服务器,然后通过生产者组件可以实现将消息写入Kafka集群中,实现消息的生产。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>输出-Kafka生产组件】
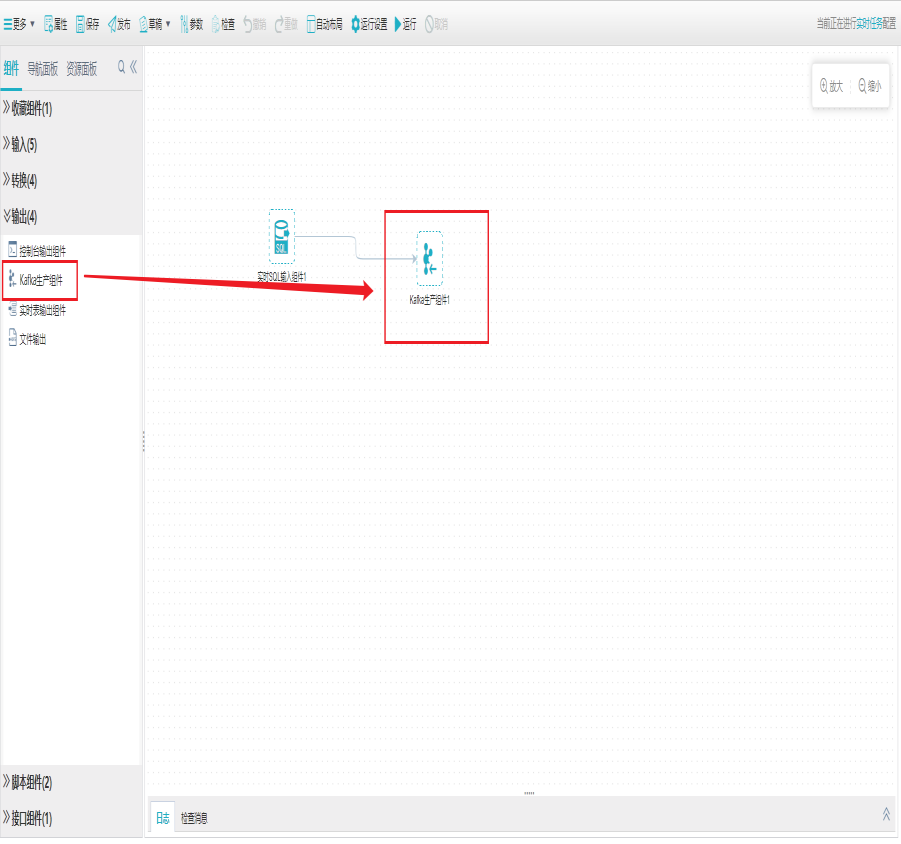
1)新建Kafka生产组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择Kafka生产组件拖拽到右边编辑区域。
2)界面设置
双击Kafka生产组件,打开设置界面,选择Kafka数据源、主题名称字段、值字段等。
Kafka设置包括Kafka服务器(从数据源选择Kafka服务器)、主题分区、key类型、value类型、offset。其中设置项中"主题"可由系统获取,用户可以直接选择某个主题。

注:Kafka生产者组件可接前置组件包括表输入、文件输入等能够提供数据输入源的一些组件。
4.2表流式输出组件
本章节主要介绍了如何利用表流式输出组件作为输出源实现数据的输出。
前提条件
用户已新建数据库连接池且前接实时任务组件。
应用场景
实时任务中数据库表既可以作为输入源,也可以作为输出源。
用户设计实时任务,拖入输入组件和处理组件以及表输出组件,然后配置好输入组件信息,处理组件处理逻辑以及表输出组件连接池和目标表及加载方式,保存后启动该任务进行抽数。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>输出-表流式输出组件】
1)新建表流式输出组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择表流式输出组件拖拽到右边编辑区域。
2)界面设置
双击表流式输出组件,打开目标设置界面,设置连接池、库表等,对字段进行映射、拾取、删除操作。

切换到附加设置界面,选择是否忽略异常、参考示例填写扩展属性,点击确定。
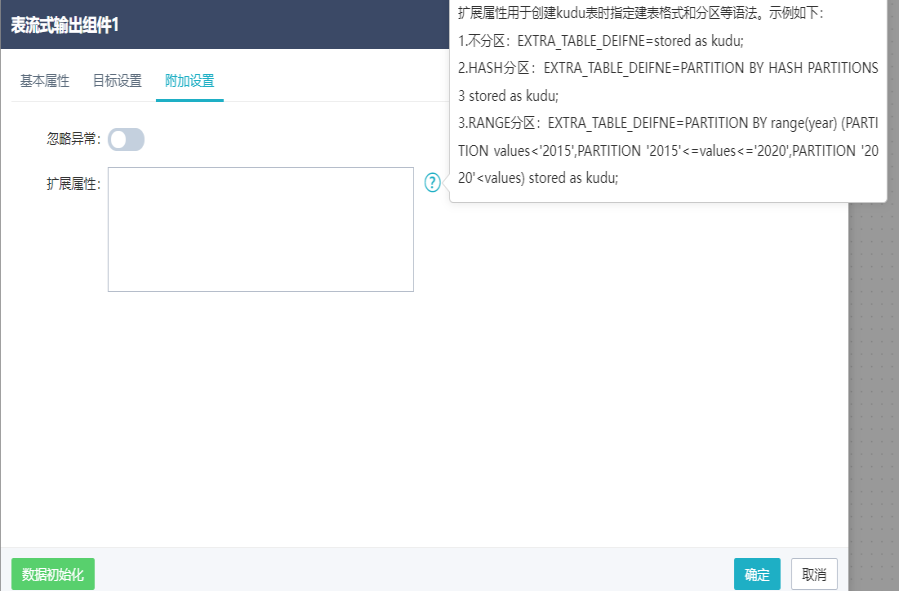
注:表流式输出组件支持关系型数据库、Hive等,可以选择对应的连接池和表,选择表后自动显示表字段,并支持表不存在则创建,支持表更新方式和批量大小设置,支持扩展属性。
表流式输出组件同现有表输出组件需求功能一致,底层使用引擎不同。可参考“3.6.4.2表输出”
4.3实时文件输出组件
本章节主要介绍了如何利用实时文件输出组件对处理后的数据储存成文件。
前提条件
用户已部署相应服务器且前接实时任务组件。
应用场景
实时任务中通常会将处理完成后的结果数据进行存储,一些数据会存储到文件中。
用户设计实时任务,拖入输入组件和处理组件以及实时文件输出组件,然后配置好输入组件信息、处理组件处理逻辑以及实时文件输出组件中服务器文件路径及字符集、列分隔符、行分割符等,保存后启动该任务进行抽数。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>输出-实时文件输出】
1)新建实时文件输出组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择实时文件输出组件拖拽到右边编辑区域。
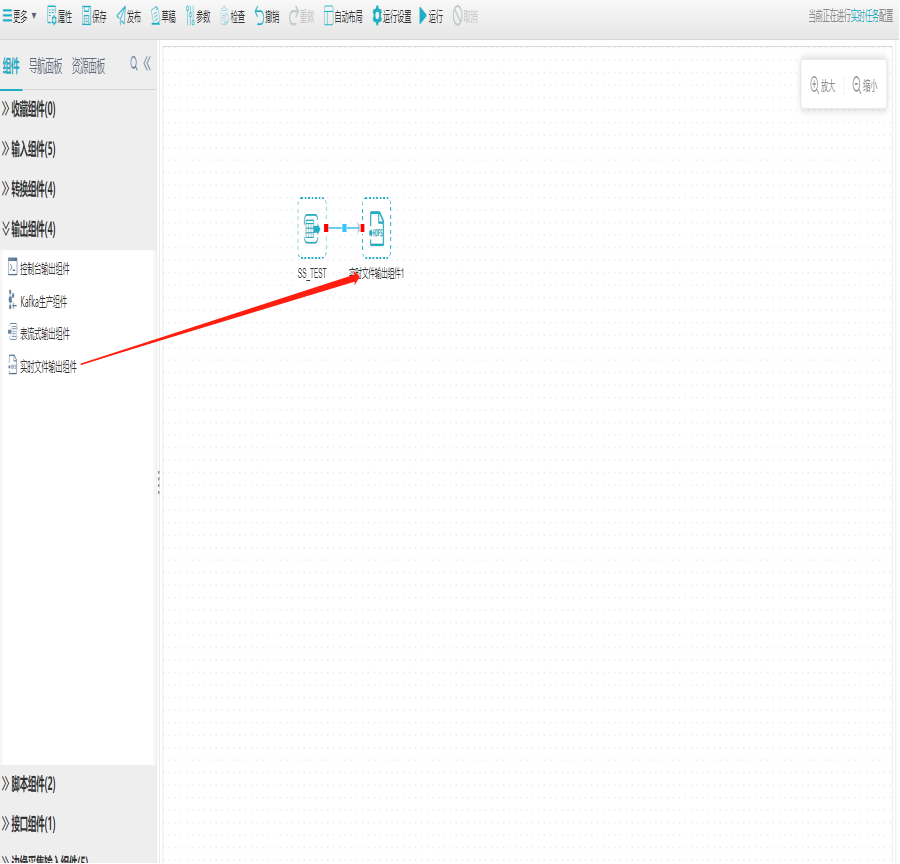
2)界面设置
双击实时文件输出组件,打开文件设置界面,设置HDFS服务器,指定文件路径、文件格式、列分隔符、行分隔符等消信息。

切换到字段列表界面,对字段进行拾取,点击确定。
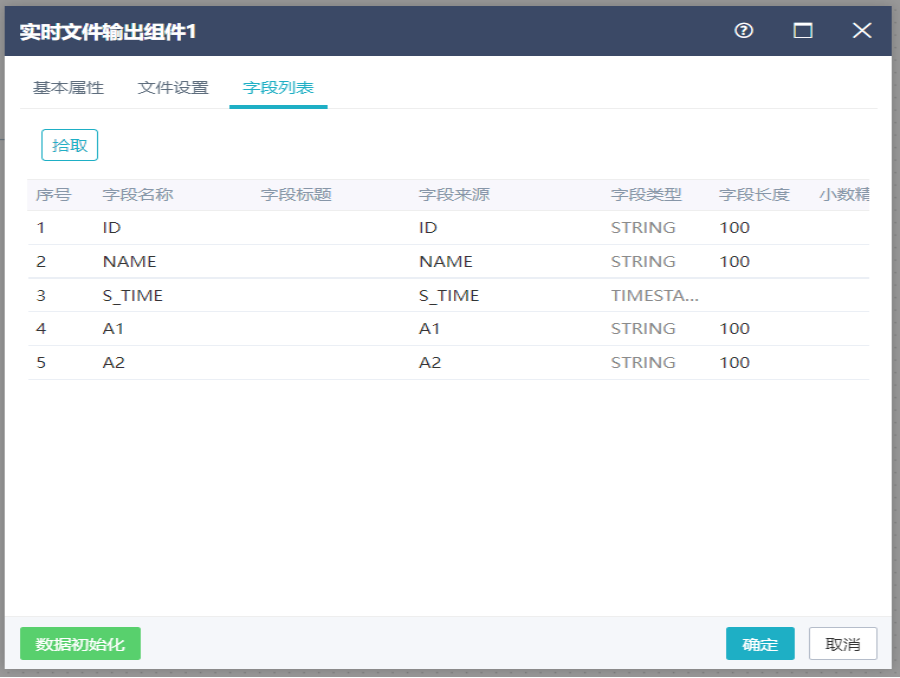
注:实时文件输出组件可以将实时任务处理的数据存储到服务器文件或者HDFS服务器文件,可设置服务器文件路径及文件名并支持宏表达式,可设置输出文件字符集、列分隔符、行分割符、文本限定符、首行是否为字段名称。
实时文件输出组件同现有平面实时文件输出组件需求功能一致,底层使用引擎不同。可参考“平面实时文件输出组件”
5.输入组件
5.1Kafka消费组件
本章节主要介绍了如何利用Kafka消费组件实现数据实时的消费。
前提条件
用户已部署Kafka服务器。
应用场景
Kafka作为一个高吞吐的分布式消息系统,以生产消费模式来生产和消费数据,Kafka本身提供消费者脚本来消费数据。
用户通过界面填写必要的配置信息,即可从Kafka消费者组件中获得数据,并进行下一步处理。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>输入-Kafka消费组件】
1)新建Kafka消费组件
打开任务编辑器,左侧组件面板中找到输入分组栏,选择Kafka消费组件拖拽到右边编辑区域。
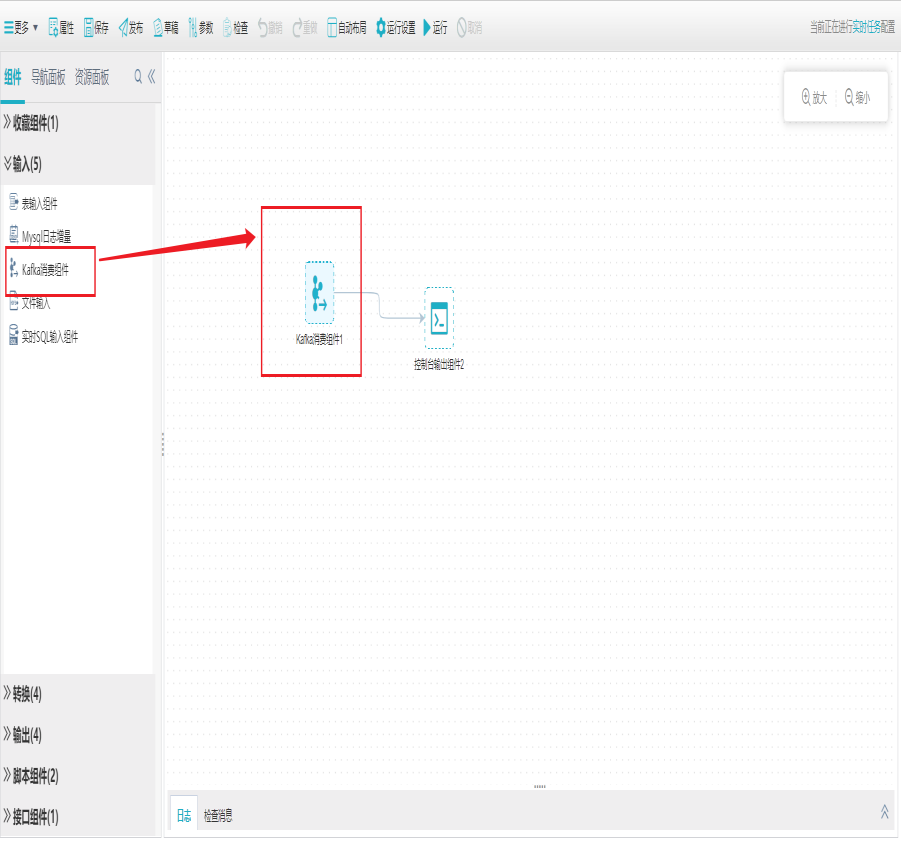
2)界面设置
双击Kafka消费组件,打开消息设置界面,选择Kafka数据源、主题等。
Kafka设置包括Kafka服务器(从数据源选择Kafka服务器)、主题分区、key类型、value类型、offset。其中设置项中"主题"可由系统获取,用户可以直接选择某个主题。
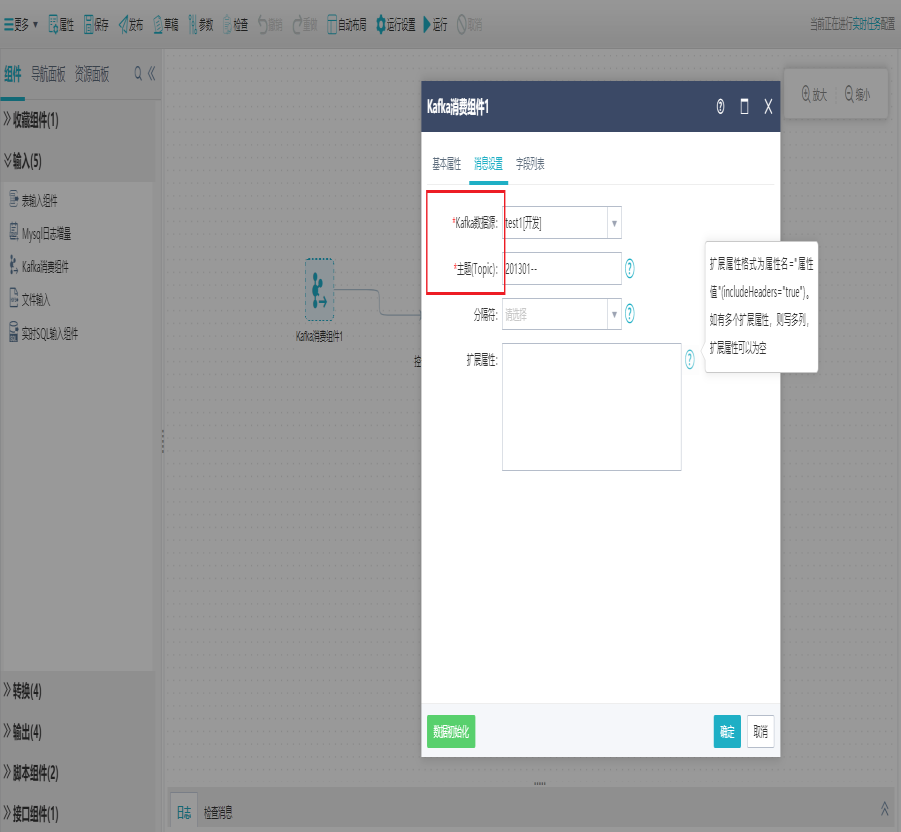
注:接收消息设置:取值类型、行分隔符、列分隔符,当每列数据为字段名-字段值格式时,可设置字段名-字段值分隔符。
1.当取值类型为分隔符方式的字符串时,才可选行分隔符、列分隔符、字段名-字段值分隔符。
2.当取值类型为JSON格式时,接收消息不需设置。
切换到字段列表界面,对字段进行删除、上移、下移操作,点击确定。
当为JSON格式时,只保留一个默认字段(COL)存储JSON消息。当为分隔符方式的字符串时,根据分隔符存储成不同的字段。

注:可参考平面文件中的格式设置。
5.2Mysql日志增量
本章节主要介绍了如何利用Mysql日志增量组件将配置好的表从源业务系统实时抽取到数仓以及增量加载。
前提条件
1、需要提前在采集服务器上安装边缘节点程序,并且启动边缘节点程序中canal
2、在使用Mysql增量组件前,需要配置边缘节点的IP地址和端口号。
应用场景
Mysql日志增量组件利用阿里开源的Canal工具对Mysql数据库的binlog日志进行实时采集分析,将变更同步到其他数据库。
用户通过配置日志型增量抽取方式,配置抽取的表,将配置好的表从源业务系统实时抽取到数仓ODS层。
用户需要从源业务系统表中增量抽取数据,但是业务系统表没有时间戳,用户通过日志型增量获取方式来做增量加载。
操作步骤
因为Mysql日志增量组件使用canal实现MySQL日志增量的数据获取与存储,因此在新建Mysql日志增量组件之前,需要提前在系统设置-参数配置-实时处理参数配置-边缘节点管理中配置边缘节点的IP地址及端口号,系统跟据配置信息,自动判断使用哪个边缘节点进行MySQL日志信息的监听。
操作入口:【任务管理>任务定义>新建-实时任务>输入-Mysql日志增量】
1)新建Mysql日志增量
打开任务编辑器,左侧组件面板中找到输入分组栏,选择Mysql日志增量组件拖拽到右边编辑区域。
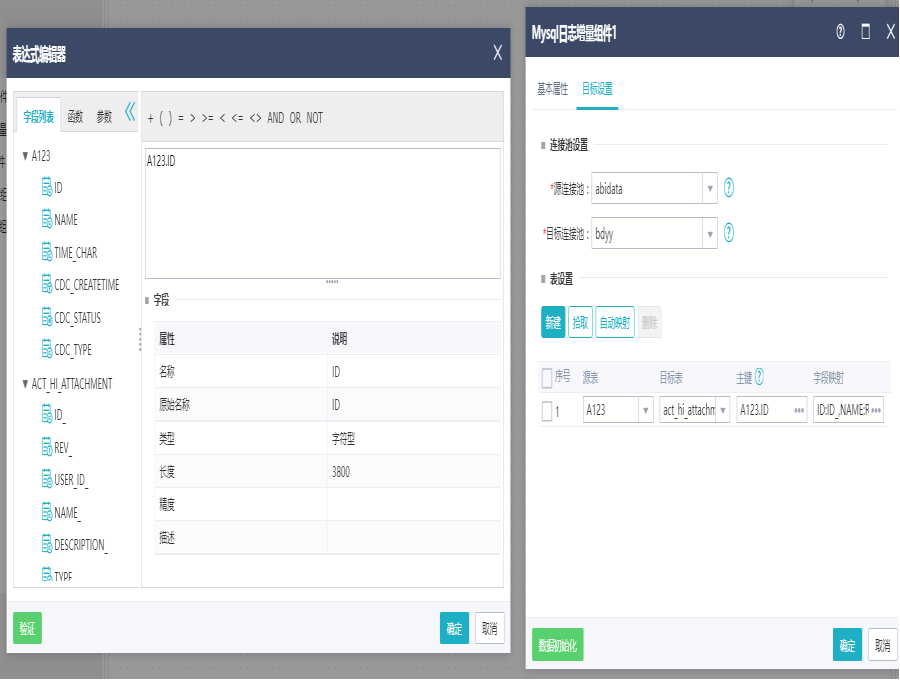
2)界面设置
双击Mysql日志增量组件,切换到目标设置界面,选择源库表、目标表,设置主键,映射匹配后点击确定。
目标设置项包括源连接池、目标连接池、源表和目标表及其映射关系、源表和目标表字段映射关系、主键字段。支持手动拾取选择源表和目标表映射,也支持根据表名自动映射。
注:在实时任务设计中,可将MySQL增量组件作为输入源,后续可接处理组件或者输出组件等。MySQL增量组件能够自动从MySQL日志中获取变化的数据,比如源MySQL库更新了一条数据,这里就能获取到该条更新数据,从而为实时任务提供增量数据源。
5.3表流式输入组件
本章节主要介绍了需要做处理的数据如何进行实时的表输入操作。
前提条件
用户已新建数据库连接池且后接实时任务组件。
应用场景
实时任务中也需要数据源作为数据输入端,数据源包含多种多样,其中数据库表也是一种输入源。
用户设计实时任务,拖入表流式输入组件,然后填写数据库连接池、表名等信息,后接大数据处理组件如过滤组件进行数据过滤后,再将数据输出到某个表或者Kafka中。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>输入-表流式输入组件】
1)新建表流式输入组件
打开任务编辑器,左侧组件面板中找到输入分组栏,选择表流式输入组件拖拽到右边编辑区域。
2)界面设置
双击表流式输入组件,打开数据源设置界面,设置源库表等。
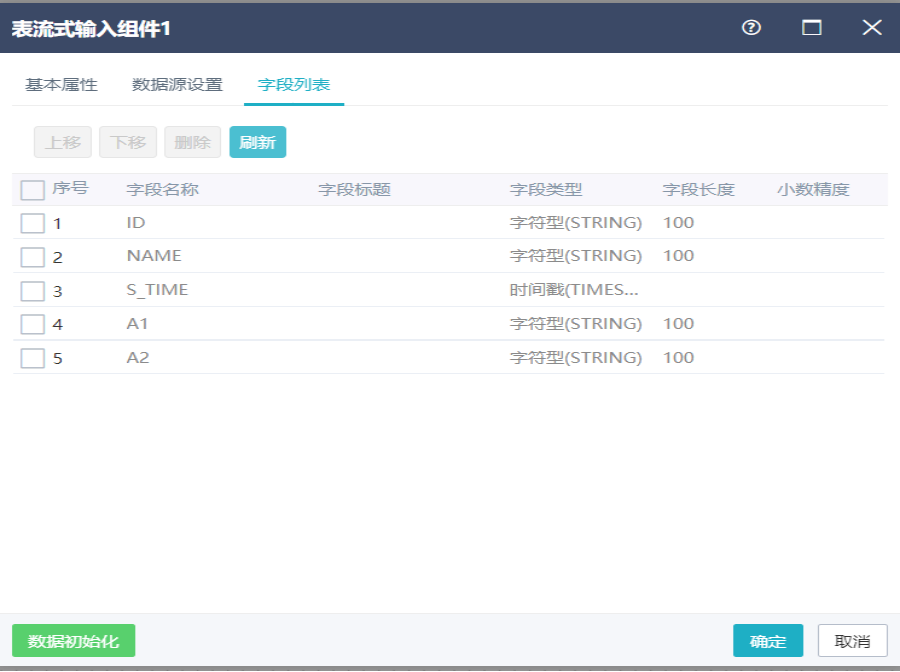
切换到字段列表界面,对字段进行删除、上移、下移操作,点击确定。
注:表流式输入组件支持关系型数据库、Hive等作为数据源,可以选择对应的连接池和表,选择表后自动显示表字段,支持获取表全量数据。
表流式输入组件同现有表输入组件需求功能一致,底层使用引擎不同。可参考“3.6.4.1表输入”
5.4实时Sql输入组件
本章节主要介绍了如何利用实时Sql输入组件,通过Sql设置进行数据的查询。
前提条件
用户已部署相应服务器。
应用场景
目前在大数据处理这块,开源Hadoop很多组件提供了各种语言进行数据处理程序开发,一些大数据组件如SparkSQL也提供了基于SQL的方式进行数据查询处理方法,不同技术人员会使用不同的方式进行大数据处理。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>输入-实时Sql输入组件】
1)新建文件输入组件
打开任务编辑器,左侧组件面板中找到输入分组栏,选择实时Sql输入组件拖拽到右边编辑区域。

2)界面设置
双击实时Sql输入组件,打开实时Sql设置界面,编写实时Sql脚本。
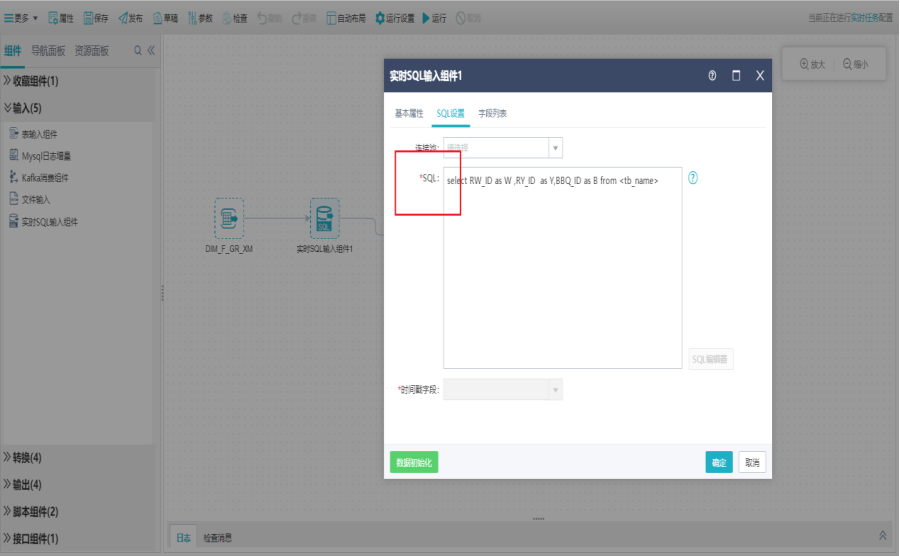
切换到字段列表界面,对字段进行删除、上移、下移操作,点击确定。
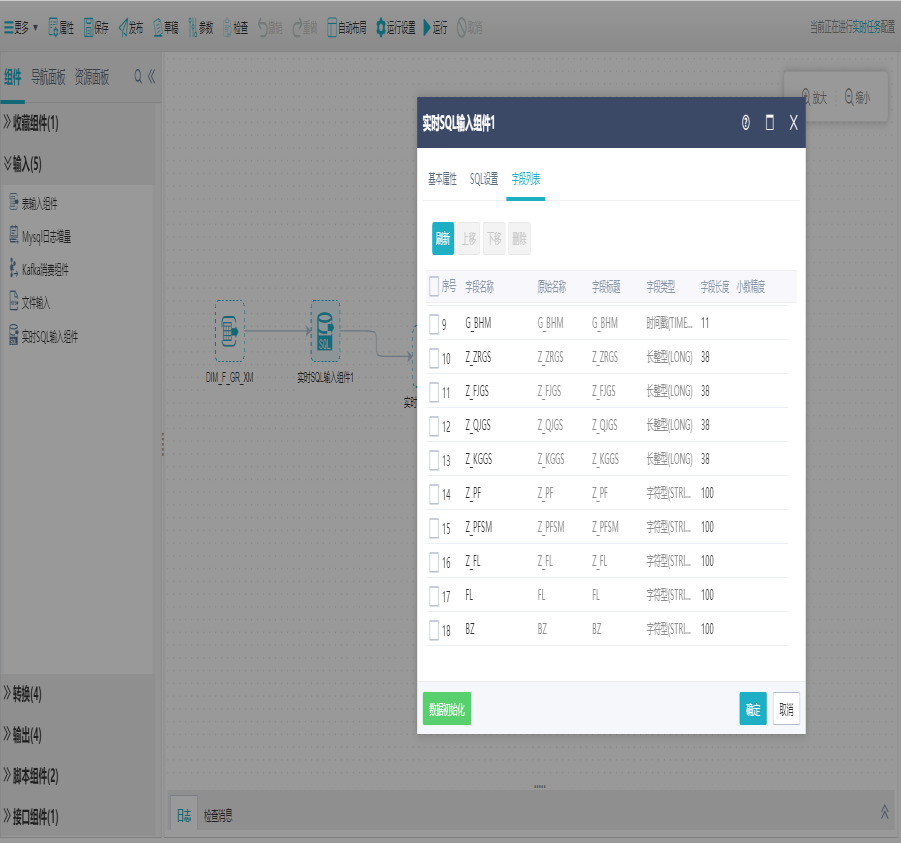
5.5实时文件输入组件
本章节主要介绍了如何利用实时文件输入组件实现文件信息实时的传输到数据库表中。
前提条件
用户已部署相应服务器。
应用场景
一般情况下,业务系统或者上游系统给下游系统提供数据,是通过定期提供一批批数据文件的方式进行的,大部分实时处理场景中都会包含文件的处理。
用户设计实时任务,拖入实时文件输入组件,然后填写日志文件的数据源文件信息或者路径,后续接实时处理组件,处理日志数据后输出到Oracle数据库表中。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>输入-实时文件输入组件】
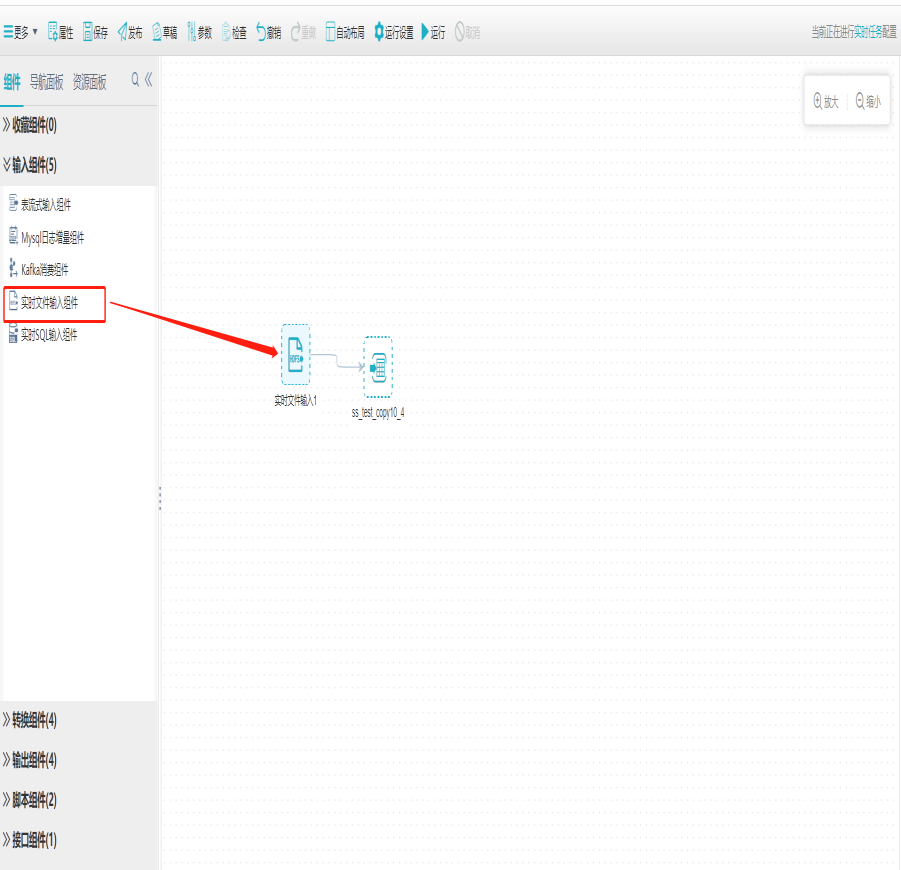
1)新建实时文件输入组件
打开任务编辑器,左侧组件面板中找到输入分组栏,选择实时文件输入组件拖拽到右边编辑区域。
 900
900
2)界面设置
双击实时文件输入组件,打开文件设置界面,选择HDFS数据源等。
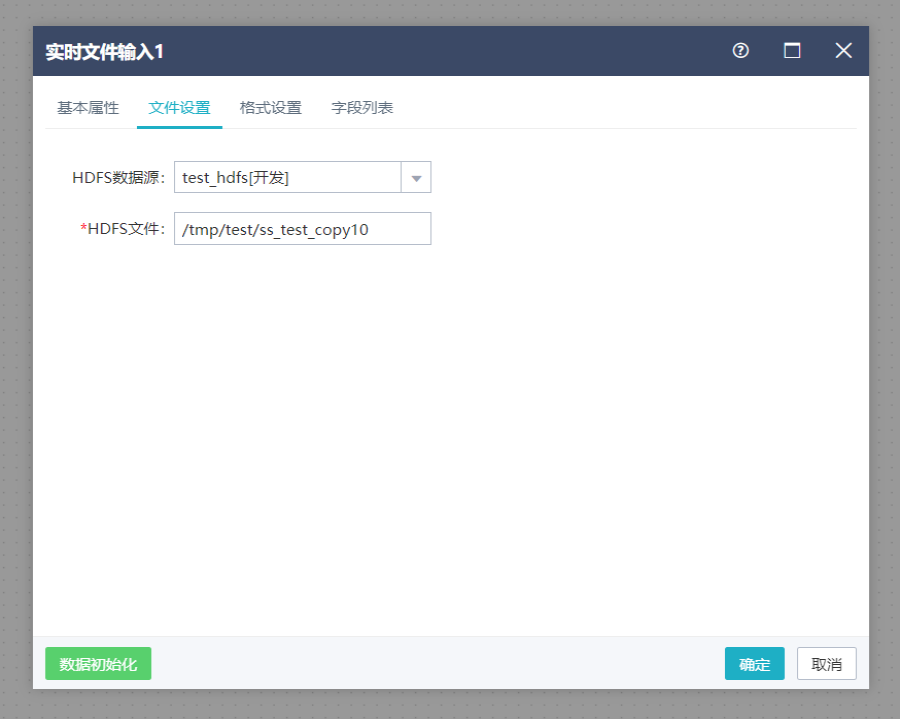
切换到格式设置界面,选择文件输出格式、列分割符、行分割符。
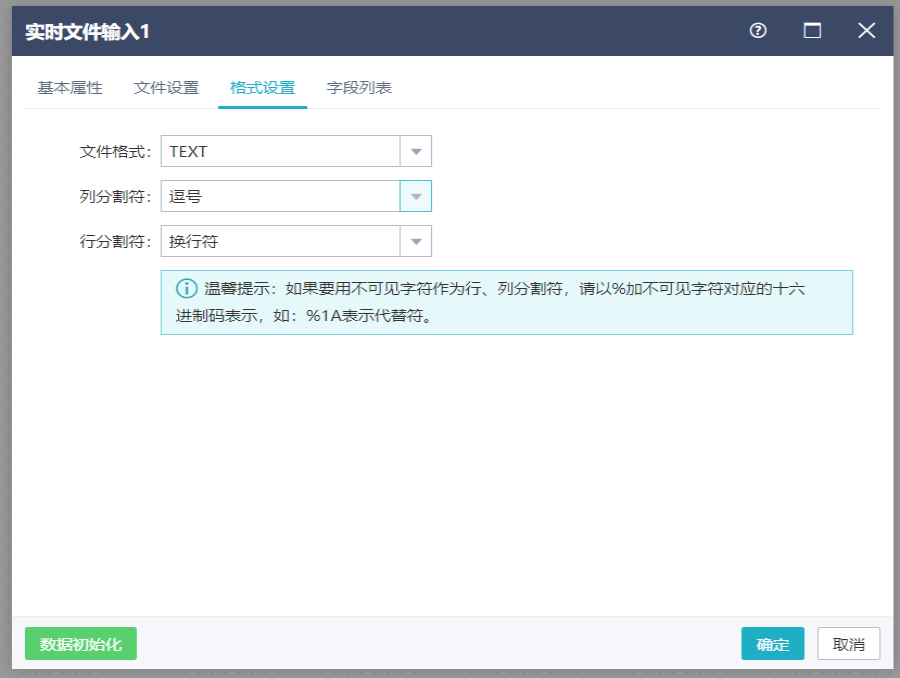
切换到字段列表界面,对字段进行删除、上移、下移操作,点击确定。
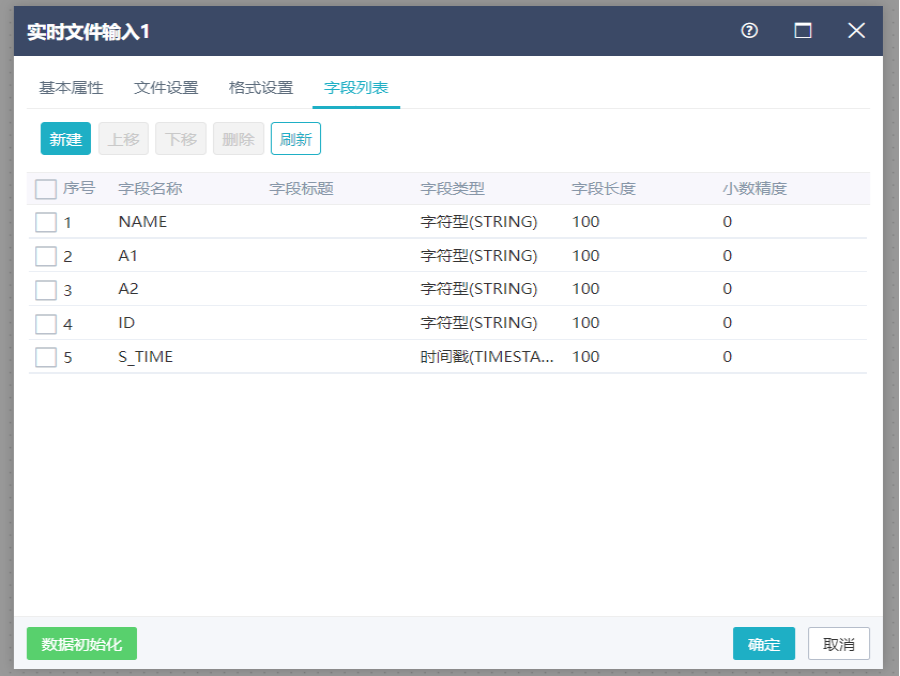
注:1.实时文件输入组件可以读取本地日志文件或者读取配置好的数据源文件(HDFS文件),设置好数据输出格式,可以将文件内容读取出去供后续组件进行处理。该组件只能后接实时任务组件。
2.文件支持单个文件读取,也支持读取目录下的一批文件,读取一批文件时,支持按照文件名格式(产品内置时间函数和正则表达式匹配方式)顺序读取。
3.实时文件输入组件同现有平面文件输入组件需求功能基本一致,底层使用引擎不同。可参考“3.6.4.6平面文件输入”
6.转换组件-实时
6.1实时表达式组件
本章节主要介绍了如何利用实时表达式组件对实时数据中的数据项进行一定的处理。
前提条件
用户已部署相应服务器。
应用场景
当需要对实时流数据需要进行一些简单处理的时候,往往在下游会使用编程语言去编写代码进行处理,后面其他实时流数据如果有类似需求也要重新进行编程实现,这样会造成不少重复编码工作量。
用户在实时流中对某些数据项进行转换,比如截取部分值、值转换等,然后才将处理后的结果分发给下游消费系统。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>转换-实时表达式组件】
1)新建实时表达式组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择实时表达式组件拖拽到右边编辑区域。
2)界面设置
双击实时表达式组件,打开字段列表界面,对字段进行新建、拾取、文本编辑、删除、上移、下移操作,点击确定。
支持的函数可以查看表达式编辑器中的函数列表。
当字段数目太多需要替换时,可以利用查找替换对某一个字段进行替换
可手动拾取字段

注:在实时任务中新加一个表达式组件,该组件可以对实时数据中的数据项进行一定的处理,可支持使用产品内置函数,同时也支持大数据平台本身的函数,如支持CDH的一些函数等,使用这些函数可对数据进行处理,比如可以通过函数去掉数据项中两端空格,将不同日期格式转换成统一的字符串格式等。
产品内置函数可先支持使用频度很高的函数(唯一值生成函数、窗口函数)。
产品支持大数据平台本身的函数,如Hive、CDH的内置函数。
6.2实时过滤组件
本章节主要介绍了如何利用实时过滤组件对数据进行过滤操作,保留有效数据传递给下游系统,保证数据传输的质量与效率。
前提条件
用户已部署相应服务器。
应用场景
当实时流数据某些数据数据质量差或者不符合采集需求需要过滤掉的时候,往往在下游会使用编程语言去编写代码进行处理,后面其他实时流数据如果有类似需求也要重新进行编程实现,这样会造成不少重复编码工作量。
用户在实时流中通过过滤组件将某些不符合条件的数据过滤掉,只保留有效的数据传递给下游消费系统。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>转换-实时过滤组件】
1)新建实时过滤组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择实时过滤组件拖拽到右边编辑区域。
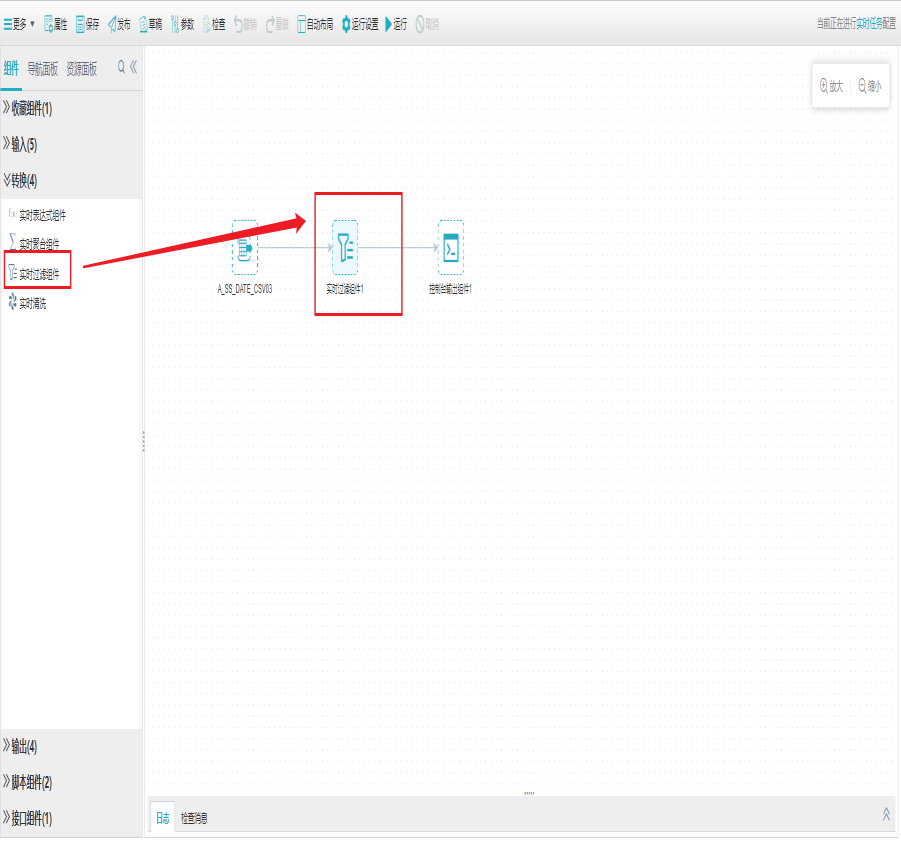
2)界面设置
双击实时过滤组件,打开字段列表界面,对字段进行拾取、上移、下移等操作。
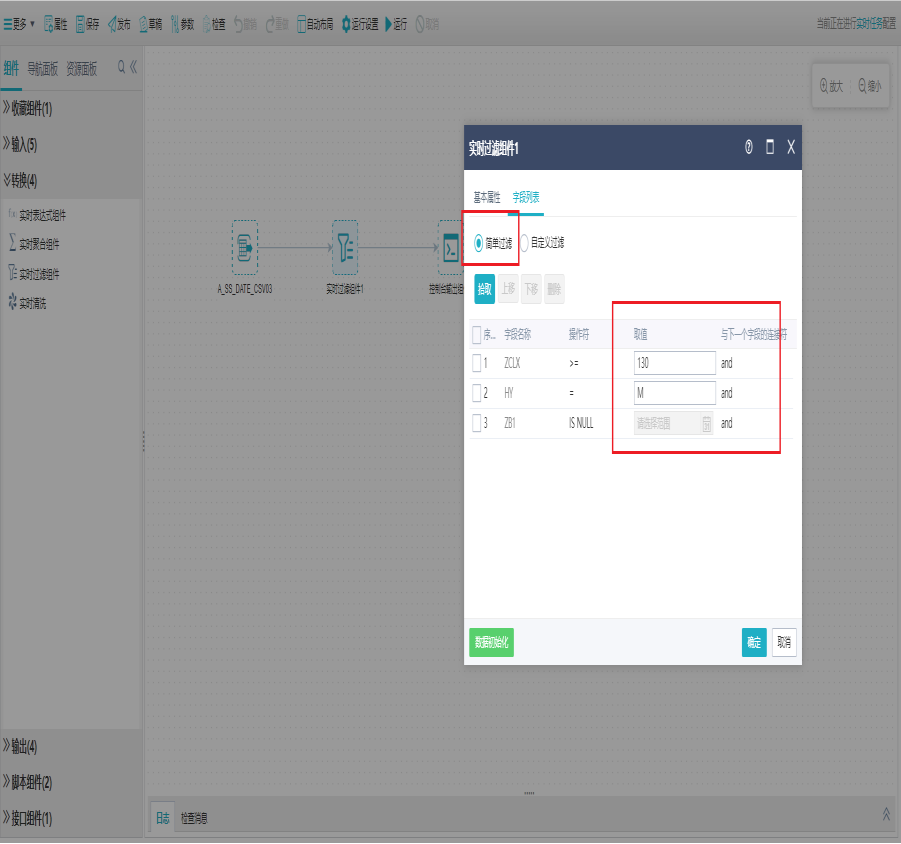
点击简单过滤,可以拾取需要过滤的字段进行过滤设置。
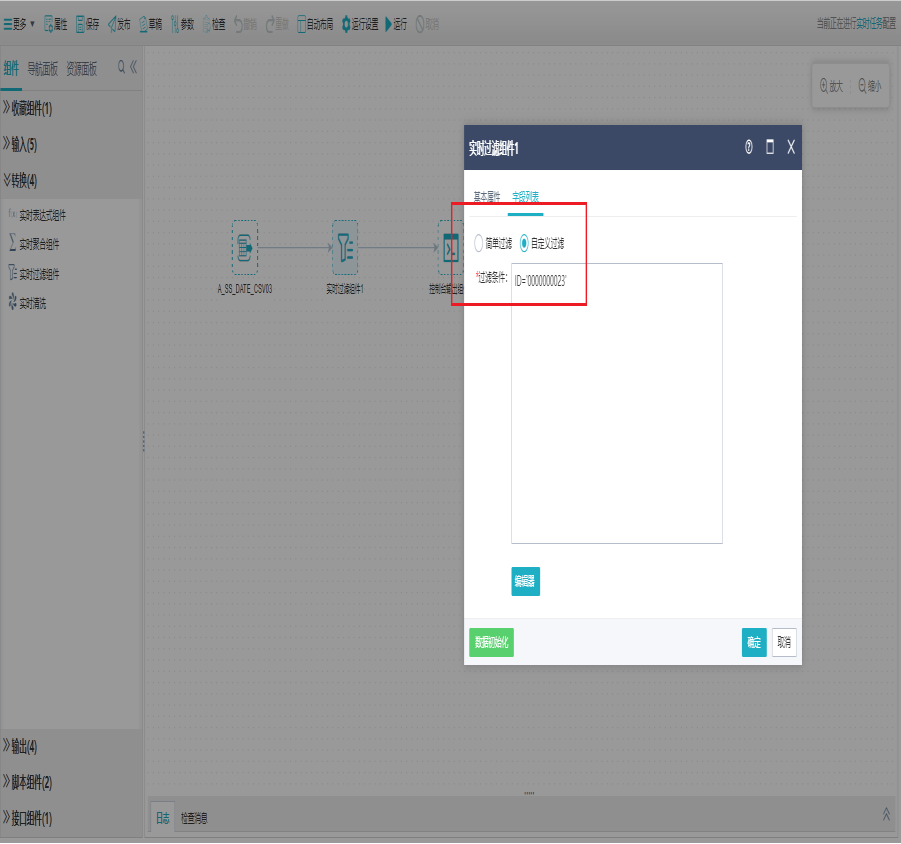
点击自定义过滤,可手写过滤条件对字段进行过滤设置。
注:实时过滤组件简单过滤可进行是否为空、大于小于等于、时间型过滤等。
6.3实时聚合组件
本章节主要介绍了如何利用实时聚合组件对数据进行实时的聚合处理。
前提条件
用户已部署相应服务器。
应用场景
当需要对实时流数据进行聚合计算的时候,往往在下游会使用编程语言去编写代码进行处理,可能一个简单的聚合功能就需要花费不少人力去实现,后面其他实时流数据如果有类似需求也要重新进行编程实现,这样会造成不少重复工作量。
用户在实时流中对网站访问人数进行统计,使用聚合组件来对访问人数进行计数,并将结果分发给下游消费系统。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>转换-实时聚合组件】
1)新建实时聚合组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择实时聚合组件拖拽到右边编辑区域。
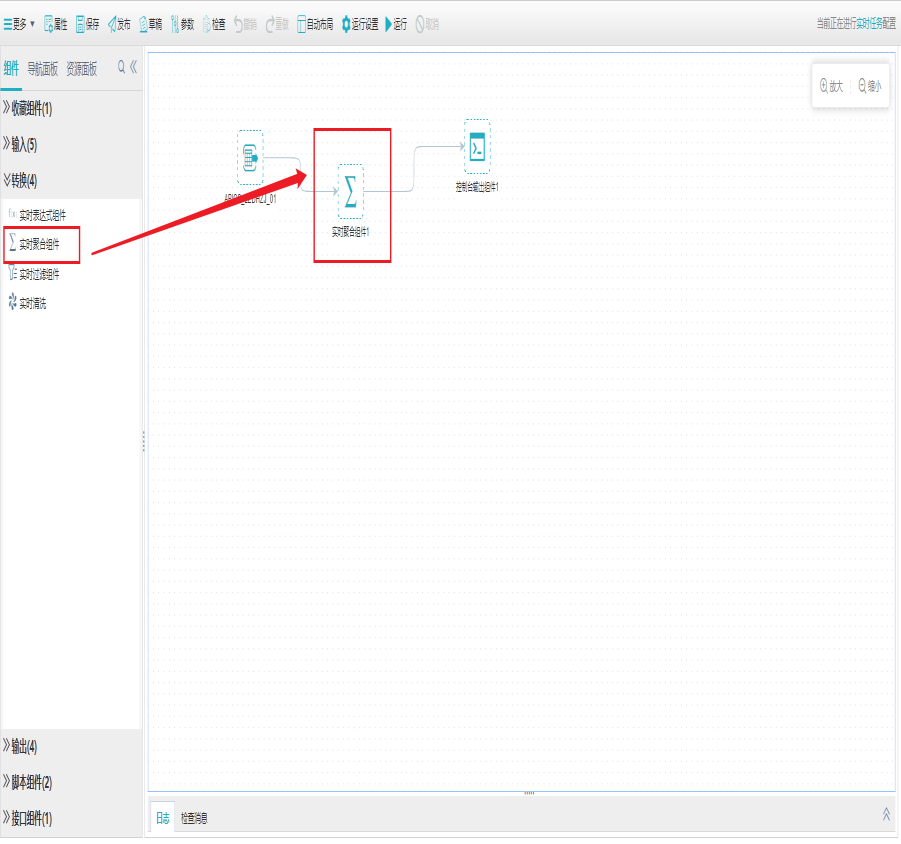
2)界面设置
双击实时聚合组件,打开字段列表界面,对字段进行新建、拾取、文本编辑、删除、上移、下移操作。
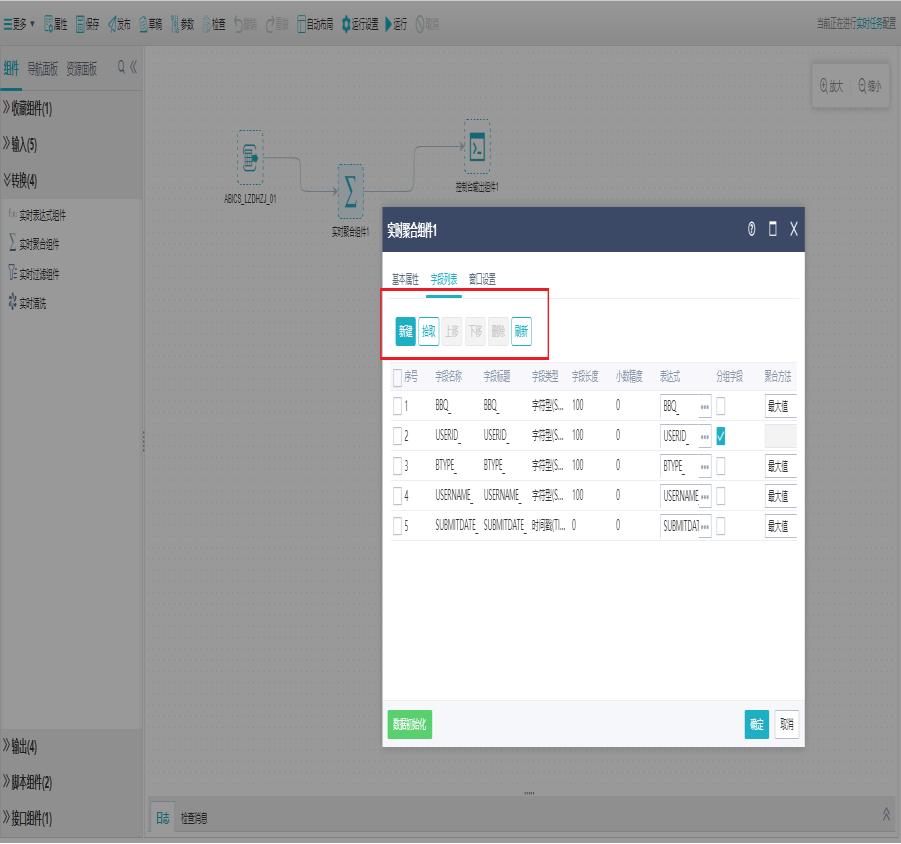
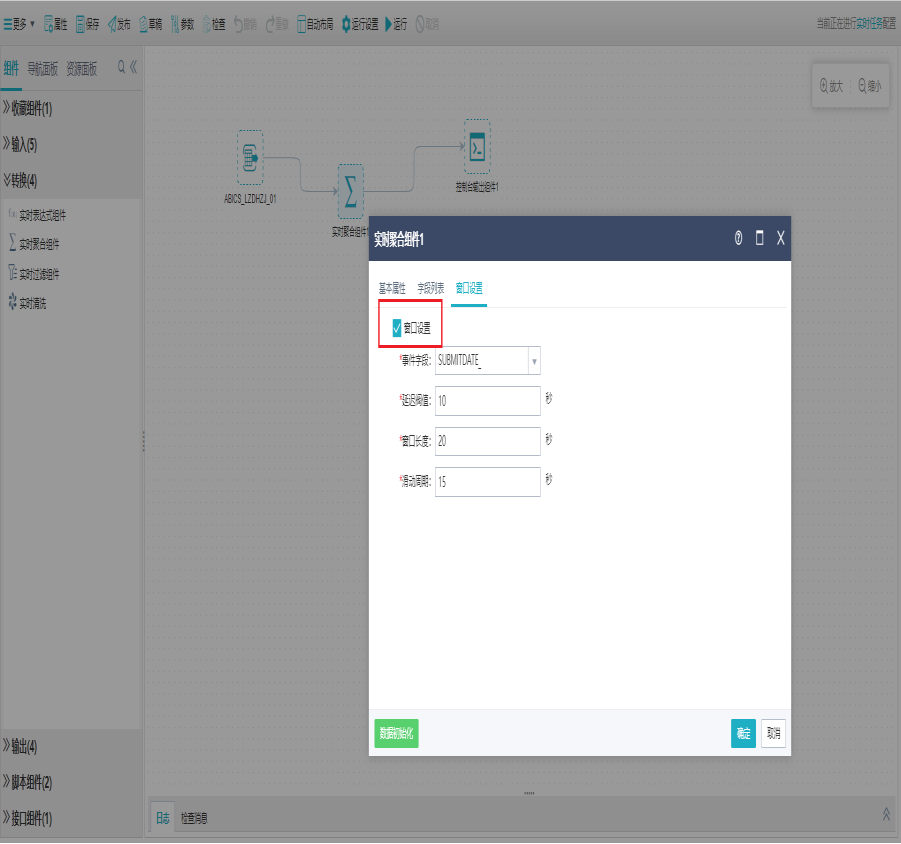
切换到窗口设置界面,可选择是否进行窗口设置,填写相关信息项,点击确定。
事件字段:下拉框显示前置列表中的时间戳字段,需要判空检测
延迟阈值:超过窗口结束时间,阈值范围内的数据都需要计算进窗口,只能是数值,需要判空检测
窗口长度:窗口起始时间与结束时间的时间差,只能是数值,需要判空检测
滑动周期:两个相邻窗口起始时间的时间差,只能是数值,需要判空检测
6.4实时清洗组件
本章节主要介绍了如何利用实时清洗组件进行数据采集落地前实时快速的清洗。
前提条件
用户已部署相应服务器。
应用场景
某些业务系统数据质量不高,针对海量数据如果使用传统方式先落地存储再质检会导致质检时间过长,且质检后数据量更大,质检性能存在问题。
通常实时数据数据量较小,方便快速清洗,基于此,针对实时数据可以在采集落地前进行必要清洗,再将清洗后的数据落地存储。
操作步骤
操作入口:【任务管理>任务定义>新建-实时任务>转换-实时清洗】
1)新建实时清洗组件
打开任务编辑器,左侧组件面板中找到转换分组栏,选择实时清洗组件拖拽到右边编辑区域。
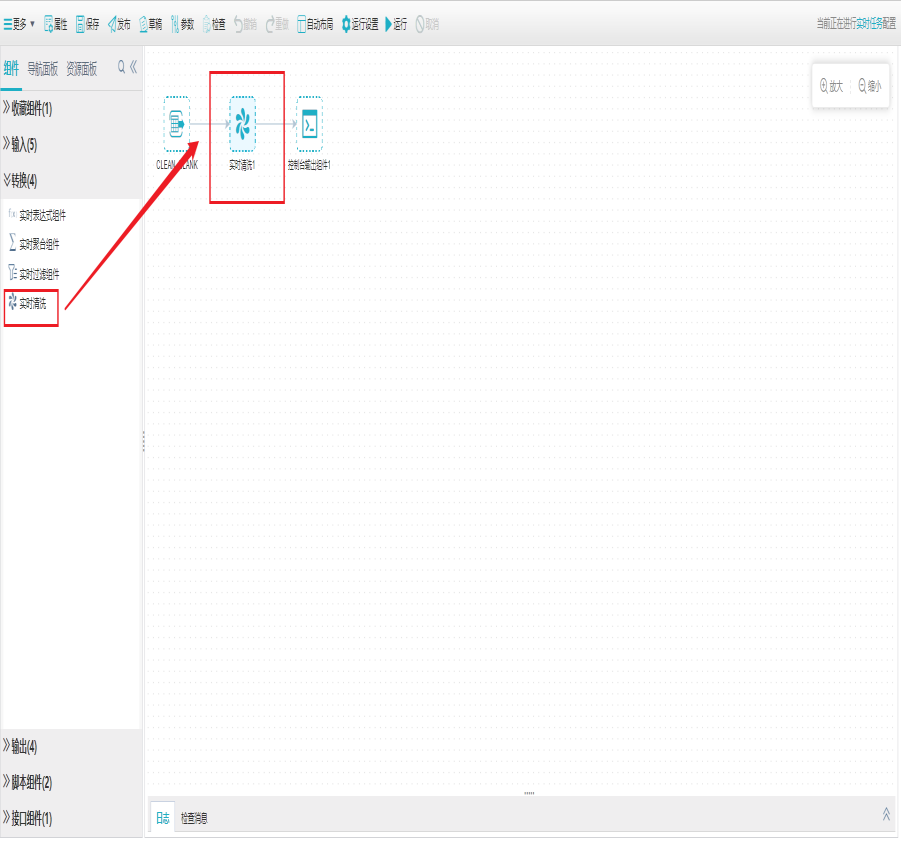
2)界面设置
双击实时清洗组件,打开规则列表界面,点击新建添加规则。
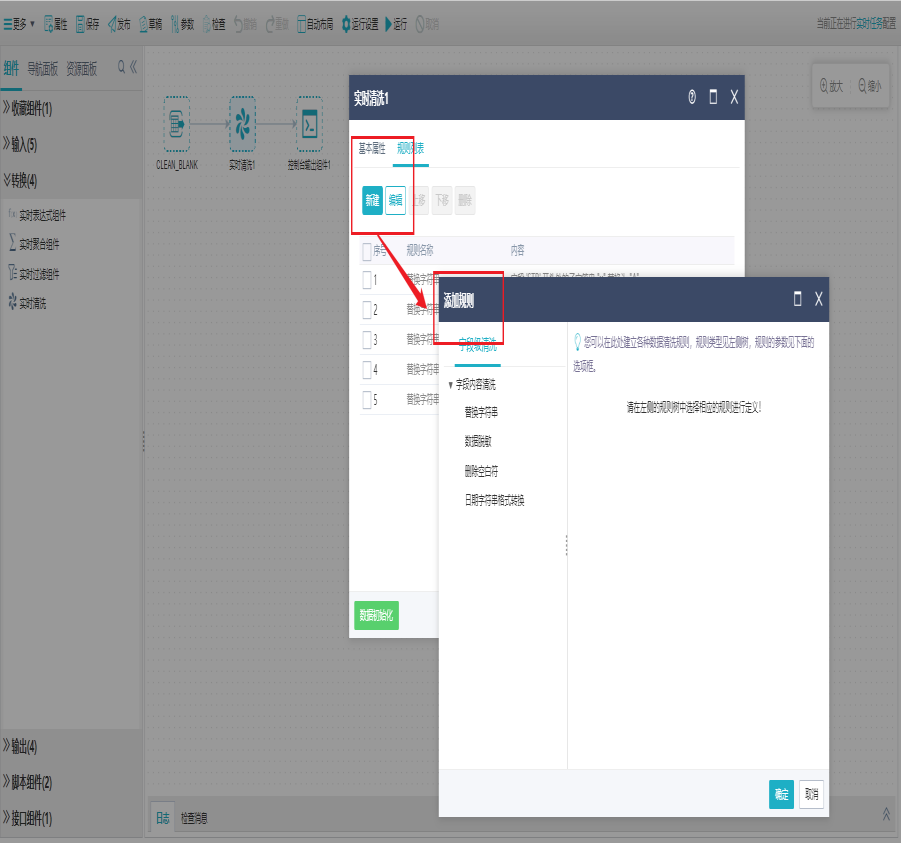
具体可清洗规则包括一下这些,列举出的为优先级较高的规则:
1)字段操作。包括多字段合并、按分隔符拆分列等。
2)字段内容清洗。包括字符串填充、替换字符串、删除字符串前后空格、删除字符串、在指定位置添加字符(串)等。
3)空值替换。将字符串指定值替换成空值、将空值替换成指定值。
4)日期类型转换。日期格式转字符格式、字符格式转日期格式等。
5)MD5处理。支持拼接多个字段生成MD5。
实时数据清洗组件同现有清洗组件需求功能一致,底层使用引擎不同。
实时数据清洗组件可支持正则表达式。


请先登录