1.设计器
交换任务设计器主要分为菜单栏、组件栏、工作区、日志栏四个部分。
菜单栏
属性 | 设置交换任务的代号及名称等属性 |
保存 | 保存交换任务 |
草稿/版本 | 切换草稿或发布版本 |
参数 | 设置交换任务的参数 |
检查 | 检查交换任务中各组件设置是否合法 |
撤销 | 撤销至上一步 |
重做 | 重做至下一步 |
自动布局 | 系统自动对交换任务重新进行布局 |
运行 | 运行交换任务 |
继续 | 调试运行到某个组件时,可以继续运行完交换任务 |
取消 | 调试运行到某个组件时,可以取消交换任务的执行 |
组件栏
可以拖入组件栏中组件至工作区
工作区
交换任务的主体部分,通过连线将组件相连接,形成交换任务数据处理流
日志栏
设计器中执行或者检查交换任务时,输出日志的地方
组件右键菜单
删除 | 删除交换任务组件 |
复制 | 复制交换任务组件 |
编辑 | 进入到交换任务组件的设置界面 |
预览数据 | 执行"运行到"该组件时,可以预览交换任务运行到此的数据记录及SQL |
数据初始化 | 组件的设置初始化到首次连线的状态 |
运行到 | 调试模式,运行到交换任务中的某个组件后,暂停执行交换任务。方便调试或定位问题。 |
2.组件基本属性
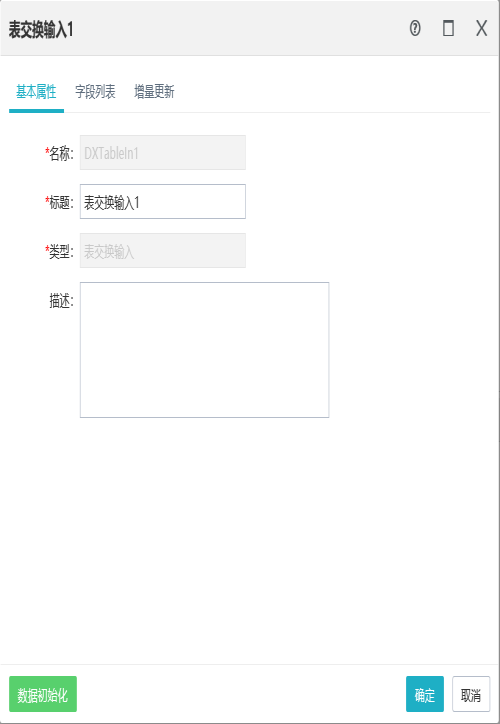
交换任务组件通用基本属性
名称 | 组件名称,后置组件需要引用前置组件字段时,需要使用如下的表达式格式,如DXTableIn2.B1 |
标题 | 交换任务设计区中显示的标题文字 |
类型 | 交换任务组件类型 |
描述 | 可以对交换任务组件加以详细描述 |
3.自定义组件
本章节主要介绍了如何创建自定义组件来自定义任务流。
3.1前提条件
用户已部署相应服务器。
3.2应用场景
用户对于平台中的组件无法满足自身交换任务的情况,可通过开发人员编写代码自定义组件来满足自身的交换任务。
3.3操作步骤
操作入口:【任务管理>任务定义>新建-批处理/交换任务>自定义组件】
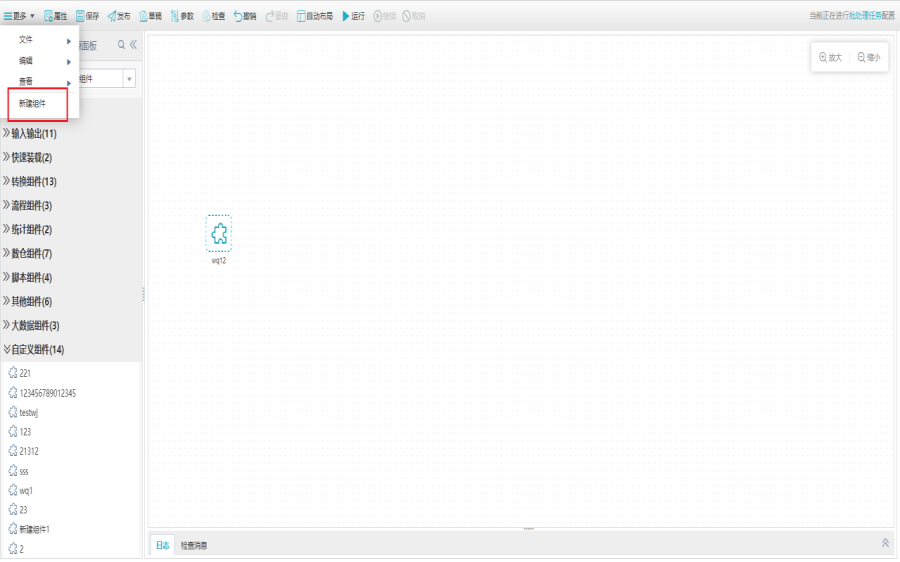
1)新建自定义组件
打开任务编辑器,点击更多,选择新建组件。
打开基本属性界面,填写组件名称、组件说明等信息。
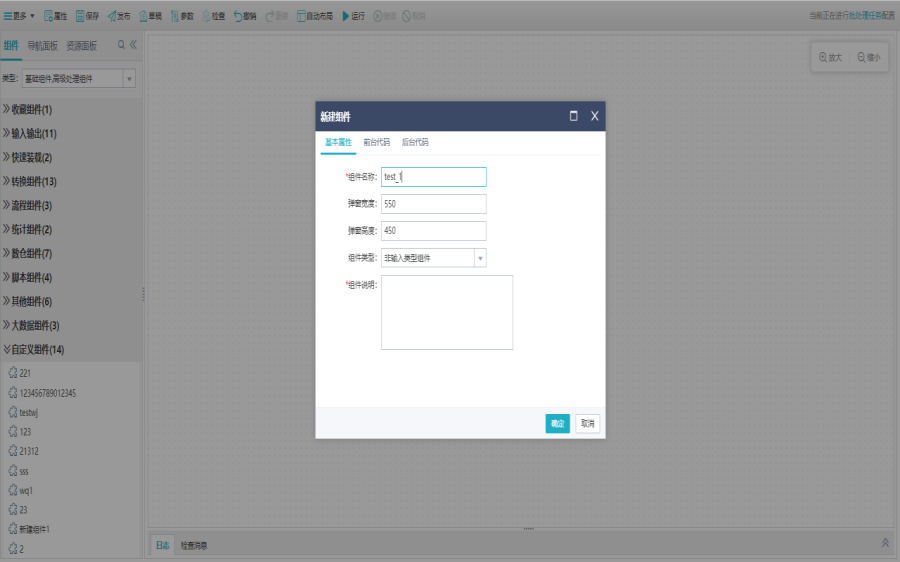
切换到前台代码/后台代码界面,编写代码后点击确定。

新建完成后可在左侧自定义组件下查看新建的组件,拖拽到右边编辑区域可使用自定义组件,右键自定义组件,点击编辑可对组件进行编辑操作。

4.传输组件
4.1表交换输入
作用:
表交换输入组件用于选择指定系统,从该系统数据库连接池中选择源表进行数据的抽取,从不同系统选择数据源以达到数据交换的目的,作为后续组件的数据来源。

其他功能同表输入
4.2表交换输出
作用:
表交换输出组件用于将前置组件获取到的结果集,加载到目的系统的连接池的数据库表中。
如果勾选临时表,交换任务执行结束后,会删除掉临时表。

其它功能同表输出
4.3批量交换表
作用:
批量交换表组件,选择一个或者多个连接池下的表,将其批量设置表名后交换到另外一个数据库中。
功能:
1.可以选择不同数据库的多张数据库表;
2.支持表名模糊搜索与Ctrl键 + 鼠标左键多选;
3.可以将所选的数据库表迁移到某个数据库中;
4.可以批量设置数据库表名,并且会对表名的长度、格式、是否存在做判断;
5.对格式与长度不规范的表名,不予执行,应该修改后执行;对于已存在的数据库表,给出了已存在警告。
基本设置:
1.源表的设置
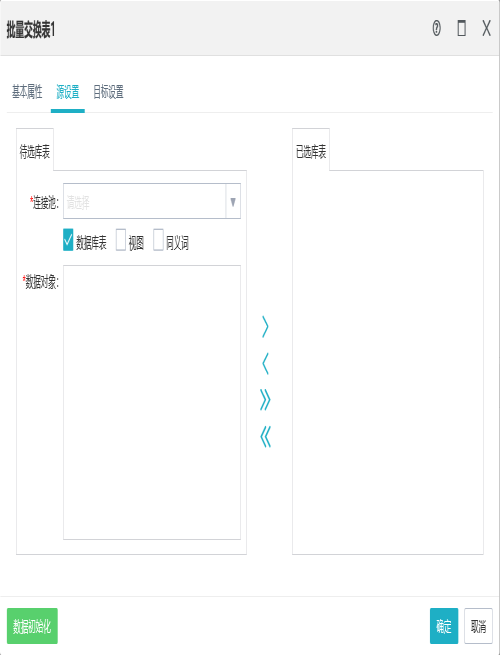
2.目标表的设置
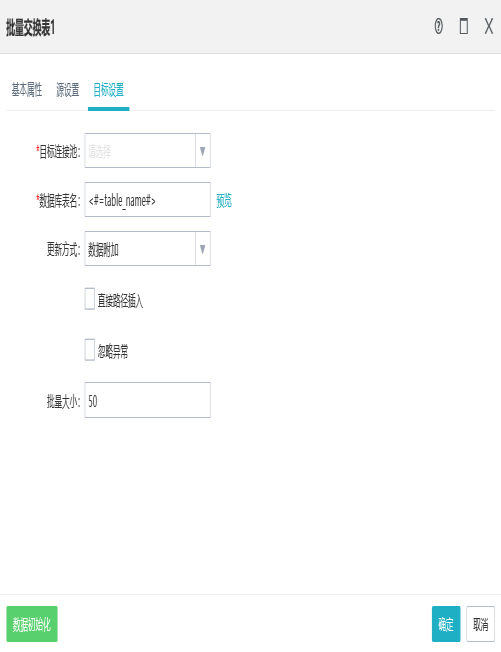
4.4批量交换到文件
作用:
批量交换到文件组件,选择一个或者多个连接池下的表,将其批量以TXT、EXCEL的文件格式输出。
功能:
1.批量交换到文件组件可以选择不同源的数据库表;
2.下载到本地的文件为.zip文件;
3.压缩文件中每个表的格式可以选择是.txt文件或者是excel文件,每种文件格式都需要有对应的设置。
基本设置:
1.源表的设置
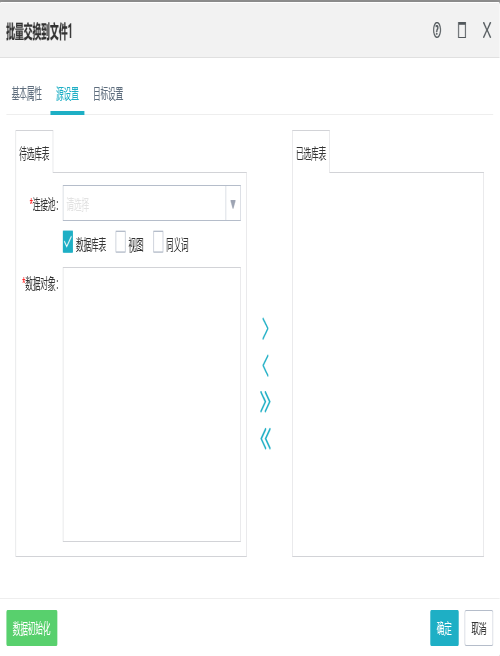
2.目标设置
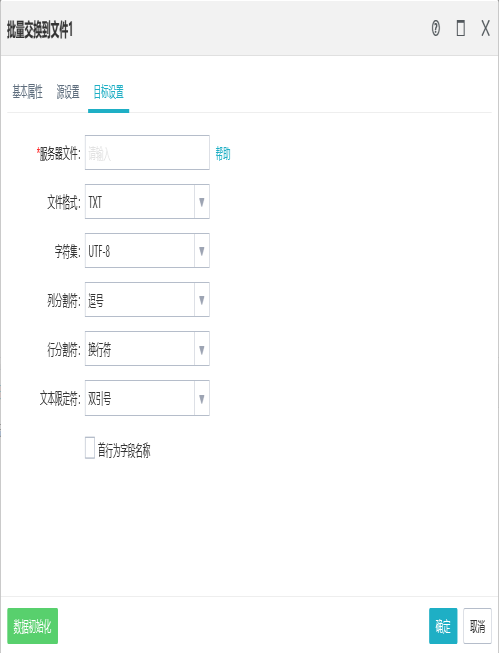
4.5文件交换表输出
作用:
文件交换表输出组件是将前置组件的输出文件目录下的文件交换到目标数据库中。
功能:
1.组件应该有且仅有一个输入组件;
2.前置组件的输出文件目录不能为空。
基本设置:

5.输入输出
5.1表输入
作用:
表输入组件用于从数据库连接池中选择源表进行数据的抽取,作为后续组件的数据来源。
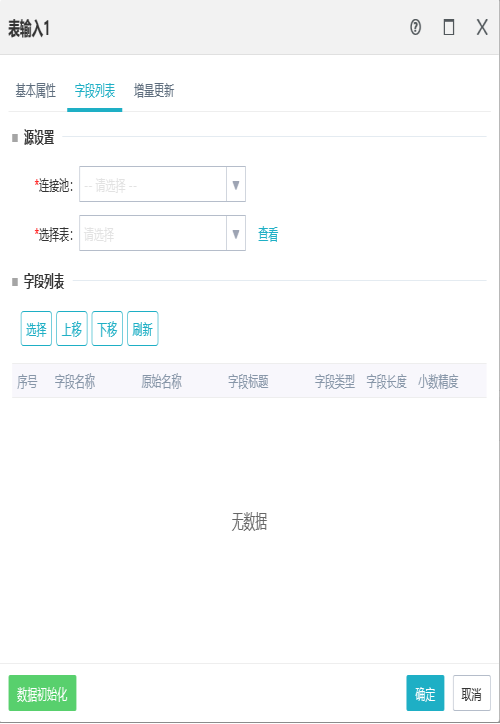
增量更新:
时间戳增量(改名为主键+时间戳增量)
它是一种基于快照比较的变化数据捕获方式,在源表上增加一个时间戳字段,业务系统中更新修改表数据的时候,同时修改时间戳字段的值。当执行交换任务表输入时,通过比较系统时间与时间戳字段的值来决定抽取哪些数据。
源表主键设置:源表中用来唯一标识记录行的字段,可多选。
时间戳字段:源表中用来存放记录更新时间的字段。
增量历史表的表名为:源表表名_TS
其历史表名为:XXX_TS
全表比对增量
设置后,会将源表主键以及比对字段的值,写入到历史表。每次执行交换任务表输入时,对源表和历史表的比对字段值进行比对,从而决定决定抽取哪些数据。
其历史表名为:XXX_FT
MD5增量
设置后,会将源表主键以及根据比对字段的数据计算出来的MD5校验码,写入到历史表。每次执行交换任务表输入时,对源表和历史表的MD5校验码进行比对,从而决定决定抽取哪些数据。
其历史表名为:XXX_MD
触发器增量
在源表上建立需要的触发器,每当源表中的数据发生变化(插入、修改),就被相应的触发器将变化的数据写入一个历史表中,当执行交换任务表输入时,通过历史表数据的值来决定抽取哪些数据。
其历史表名为:XXX_TR
最大值增量
其他增量方式会在源表的库里面创建一张增量数据表,但是有时候对于数据库安全性要求较高时不允许用户改动源库,此时需要一种新的增量:最大值增量来实现该功能。
最大值增量更新方式,与上一次记录的时间戳字段最大值比对,大于上次记录的最大值认为是最新数据进行输出。
变量字段:源表中用来存放记录更新时间的字段(必填项)。
5.2表输出
作用:
表输出组件用于将前置组件获取到的结果集,加载到目的连接池的数据库表中。
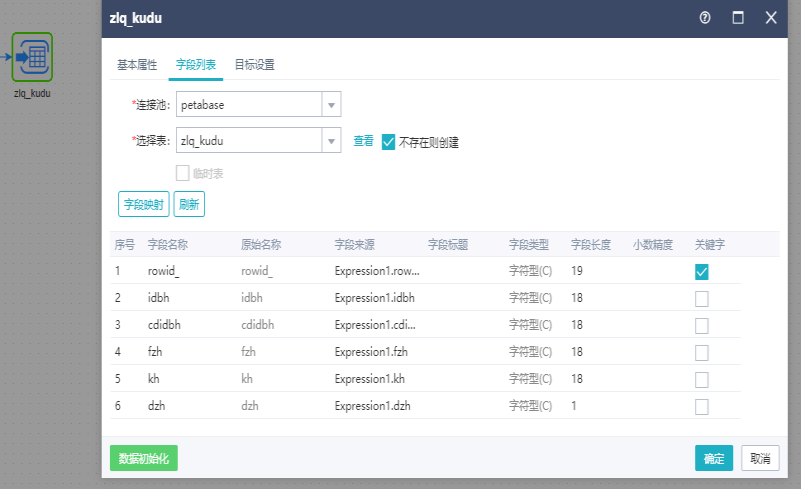
设置字段映射
源表字段和目标表字段对应。
数据附加
将源数据追加到目标目的表中,若某条源数据记录在目标中已经存在,则忽略该条源数据。
数据覆盖
先将目标表清空(delete),在将源数据插入目标表中。
勾选截断表时,会以truncate table的方式清空表。
数据更新
更新目标表中已有的数据,源数据在目标表中的不存在的话,将不作处理。
更新插入
源数据如果在目标表中不存在,则插入该条数据;源数据如果在目标表中存在,则更新该条数据。
直接路径插入
勾选后,能提高插入数据的效率。
批量大小
插入数据时,每次批量提交的记录行数。
5.3SQL输入
作用:
支持直接以查询类SQL语句作为数据源,进行数据抽取,但不支持增量更新。
5.4主题表输入
作用:
基本和表输入组件一致,不同的是表输入是选择物理表,而主题表输入选择的是主题表。(主题表来源于数据集创建的主题表)

主题表的增量更新方式可参考表输入的增量更新。
5.5主题表输出
作用:
主题表输出组件和表输出组件一样,也是作为输出端,目标组件。界面设置基本一样,不同的是主题表输出是输出到主题表的。
主题表输出的更新方式可参考表输出。
5.6平面文件输入
作用:
可以读取服务器上的TXT/CSV等文本文件作为数据源,进行数据抽取。
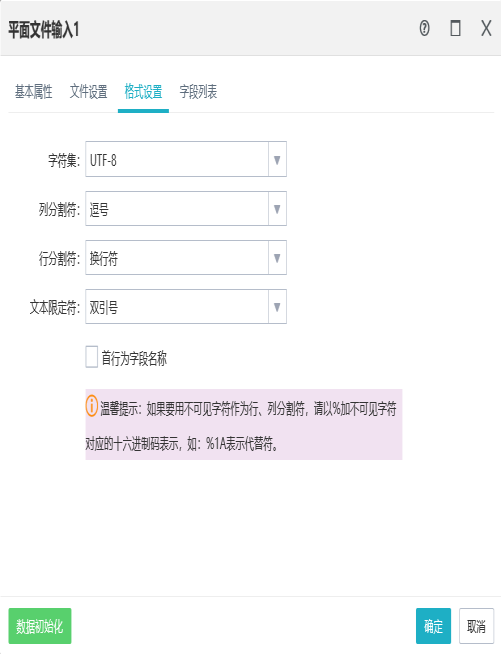
格式设置:
在指定平面文件输入的基本属性和文件路径后,可对文件的拆分格式进行设置,包括字符集列分隔符、文本限定符,设置首行为字段行,明确文件拆分的分割方式。
5.7平面文件输出
作用:
可以将前置组件获取到的结果集,写入到服务器上指定的TXT/CSV文本文件中。
需要设置服务器文件路径,字符集,列分隔符,以及文本限定符。
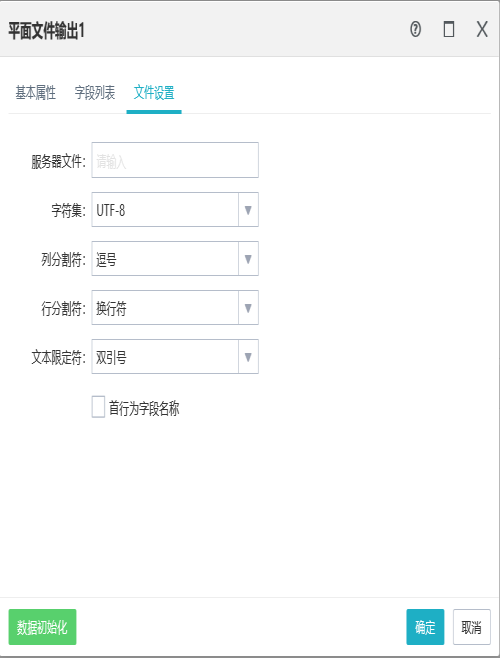
不同于平面文件输入,平面文件输出的文件设置中包含了文件的格式设置。
首行为字段名称:勾选之后,就会将字段列表界面的字段信息写入到文件的首行中,不勾选,则不写入字段信息。
5.8EXCEL输入
作用:
支持从EXCEL文件中获取数据进行交换任务处理,EXCEL输入组件支持的文件后缀为XLS和XLSX,可读取文件夹中多个Excel文件。

格式设置:在指定EXCEL输入的基本属性和文件路径后,可对EXCEL的拆分格式进行设置,包括sheet页字,起始行和起始列,设置首行为字段行,明确EXCEL拆分的分割方式。
sheet页:通过下拉框选择要读取的数据的sheet页名。当正确设置了文件路径时,切换到该页就会将excel文件的所有sheet页加载到下拉列表。
起始行:设置从第几行开始读取数据,默认为1。
起始列:设置从第几列开始读取数据,默认为1。
首行为字段名称:设置是否从sheet页所在的第一行读取字段信息。
sheet页名称作为一列数据:勾选后,生成的临时表会多加一列 sheetName_,该列的值恒为sheet页名称。
中文字段转拼音首字母:勾选后,读取Excel文件时,字段名为中文,将自动转为拼音首字母。
开启模板检查:模板检查会根据字段列表设置中的字段详情来对EXCEL文件进行检查,如果按照格式设置中的起始行,起始列读取到的字段个数与字段列表中的字段个数不一致,则检查不通过。模板检查与字段过滤功能互斥,不可同时勾选。
开启字段过滤:字段过滤会根据字段列表设置中的字段详情来对EXCEL文件中的字段进行过滤,如果按照格式设置中的起始行、起始列读取到的字段名称不与字段列表中的任何一个字段的字段名称(或字段标题)相同,则忽略该字段,如果所有字段都不相同,则忽略该文件。字段过滤与模板检查功能互斥,不可同时勾选;勾选【中文字段名转拼音首字母】会影响字段过滤效果
勾选【匹配所有字段】会在所有字段都满足过滤条件时才读取EXCEL文件内容。
5.9EXCEL输出
作用:
将经过交换任务处理后的数据落地到EXCEL文件中进行保存,和表输出组件一样作为输出端。EXCEL输出组件支持保存的文件格式为XLS,XLSX。
5.10HDFS文件输入
本章节主要介绍了如何利用HDFS文件输入组件将HDFS文件作为输入源读取出文件内容,并通过后续组件进行处理。
前提条件用户已部署HDFS服务器。
应用场景越来越多的企业都会建立自己的大数据平台,大部分企业都会采用Hadoop生态组件进行架设,同时大数据平台要求能与其他业务系统数据、外部数据等进行数据之间交换。
用户在数据工厂中选择HDFS文件输入组件,配置具体文件路径,后面接入文本文件输出,从而将HDFS文件卸载到指定的服务器中。
操作步骤操作入口:【任务管理>任务定义>新建批处理任务>HDFS文件输入组件】
1)新建HDFS文件输入组件
打开任务编辑器,左侧组件面板中找到输入输出分组栏,选择HDFS文件输入组件拖拽到右边编辑区域。
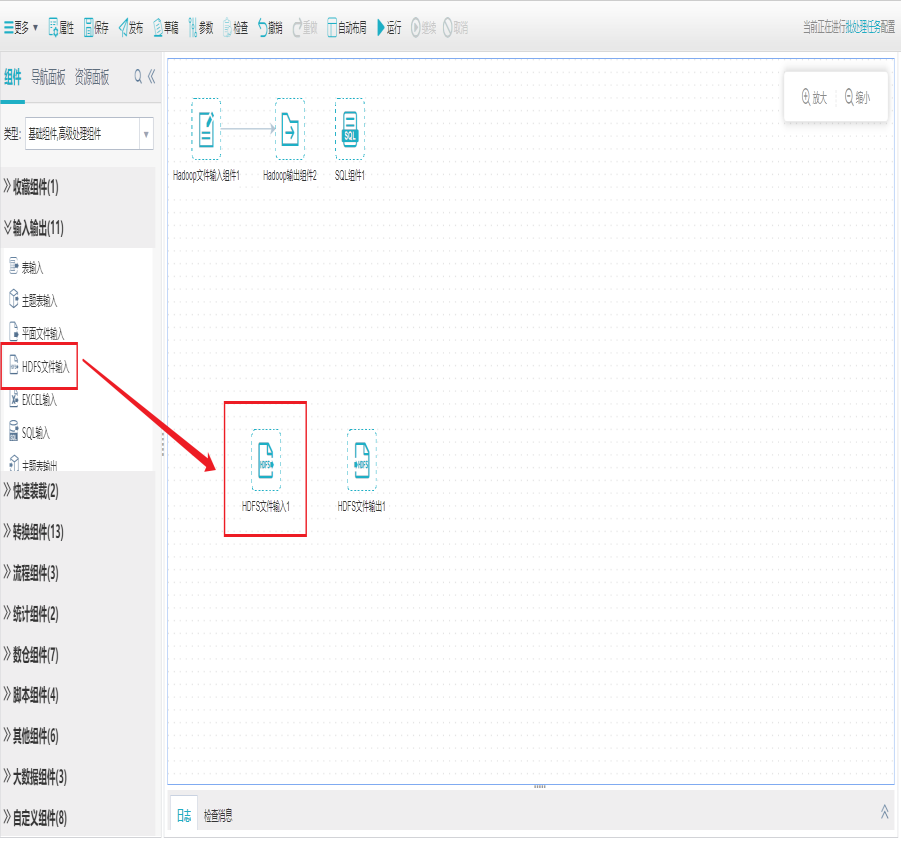
2)界面设置
双击HDFS文件输入组件,打开字段列表界面,新增字段,也支持删除、上移、下移字段。

切换到文件设置界面,设置HDFS服务器、文件路径、文件格式、压缩方式以及支持扩展属性,点击确定。
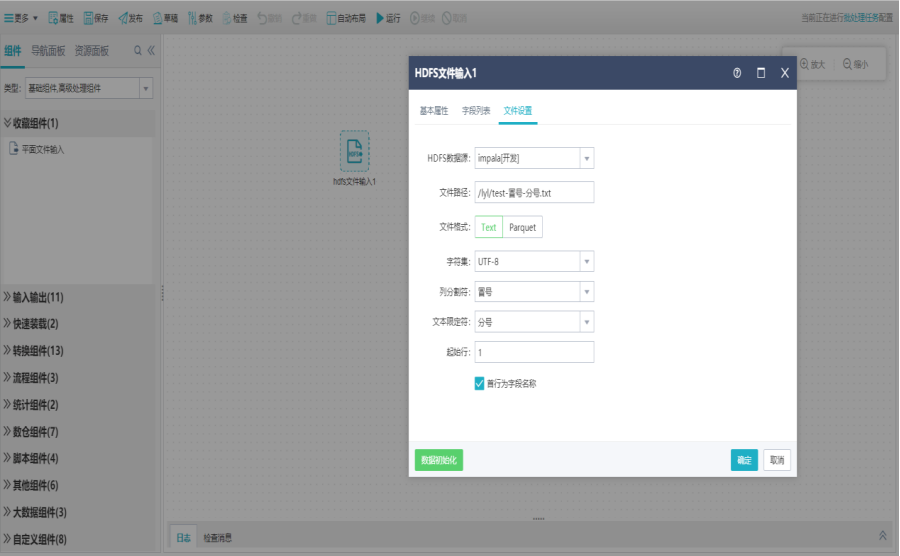
注:界面设置说明请参考“大数据组件”
HDFS文件输入组件选择了文件类型为TXT时,需支持列分隔符、文本限定符、起始行设置,支持勾选是否将首行作为字段名称。
5.11HDFS文件输出
本章节主要介绍了如何利用HDFS文件输出组件将本地文件读取后输出为HDFS文件
并储存到指定服务器中。
前提条件用户已部署HDFS服务器。
应用场景越来越多的企业都会建立自己的大数据平台,大部分企业都会采用Hadoop生态组件进行架设,同时大数据平台要求能与其他业务系统数据、外部数据等进行数据之间交换。
用户在数据工厂中选择HDFS文件输入组件,配置具体文件路径,后面接入文本文件输出,从而将HDFS文件卸载到指定的服务器中。
操作步骤操作入口:【任务管理>任务定义>新建批处理任务>HDFS文件输出组件】
1)新建HDFS文件输入组件
打开任务编辑器,左侧组件面板中找到输入输出分组栏,选择HDFS文件输出组件拖拽到右边编辑区域。

2)界面设置
双击HDFS文件输出组件,打开字段列表界面,可勾选或批量勾选输出字段。
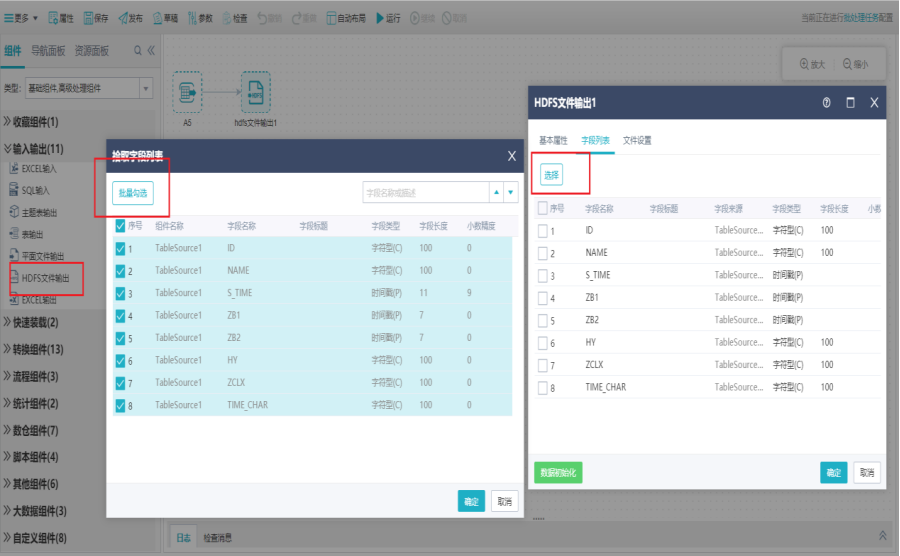
切换到文件设置界面,设置HDFS服务器、文件路径、文件格式、压缩方式以及支持扩展属性,点击确定。

注:界面设置说明请参考“大数据组件”
HDFS文件输入组件选择了文件类型为TXT时,需支持列分隔符、文本限定符、起始行设置,支持勾选是否将首行作为字段名称。
6.快速装载
6.1Greenplum装载
该组件采用Greenplum库自带的gpload快速装载的方式迁移表数据,通过执行insert、update、merger等操作将数据装载到目标数据库表中。
页面设置分为字段列表页和目标设置页,字段列表页面定义了文本数据中的字段和目标表字段的映射关系;目标设置可以定义解析文本数据的方式。
字段列表页面:
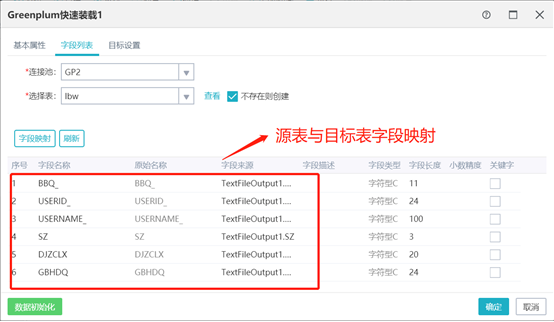
目标设置页面:

使用该组件前需要在产品服务器上安装gpload(参考文档gpload的安装);需要Greenplum库所有的节点都可以访问文本文件的服务器,因为gpload使用的是gpfdist文件系统,该文件系统会随机将文件发送给某个Greenplum节点。
6.2Oracle卸载
利用数据库客户端自带的命令行工具进行文本数据的快速卸载。
页面设置分为字段列表页和设置页。字段列表页面可以拾取删除前置组件字段;目标设置可以定义解析文本数据的方式。
字段列表页面:
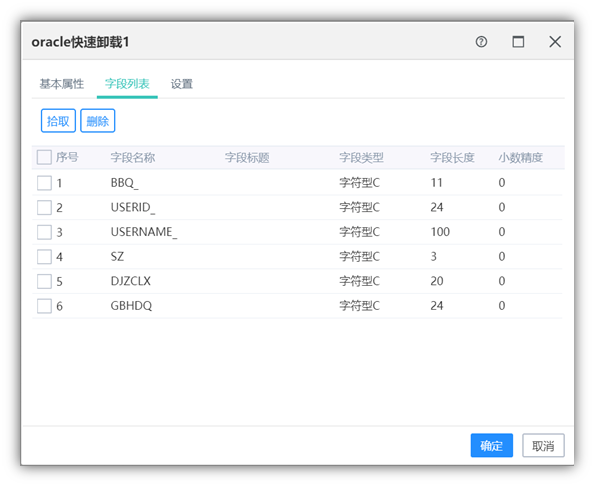
目标设置:
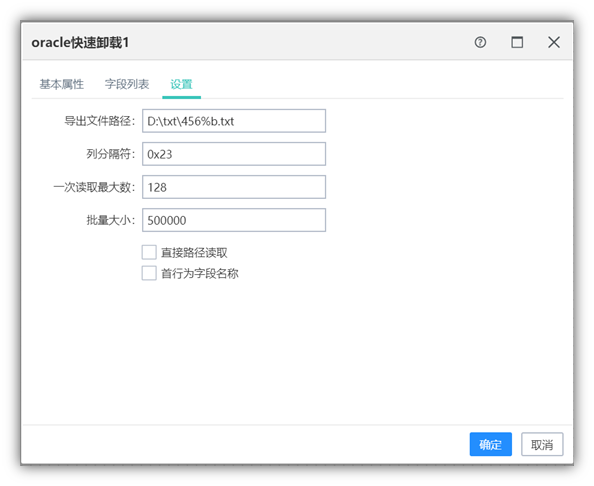
使用前需要在产品服务器上安装sqluldr2(注意环境变量配置),sqluldr2本身不支持连接远程数据库所以要在安装的时候要装oracle客户端;如果设置了批量大小,文件名称要以%b结尾,批量大小的作用是根据设置的行数,每多少行数据生成一个文件;文件所在路径要真实存在,sqluldr2不会自动创建不存在文件夹。
6.3Oracle装载
作用:
利用数据库客户端自带的命令行工具进行文本数据的快速装载,对于大数据量的处理比insert的效率高很多。
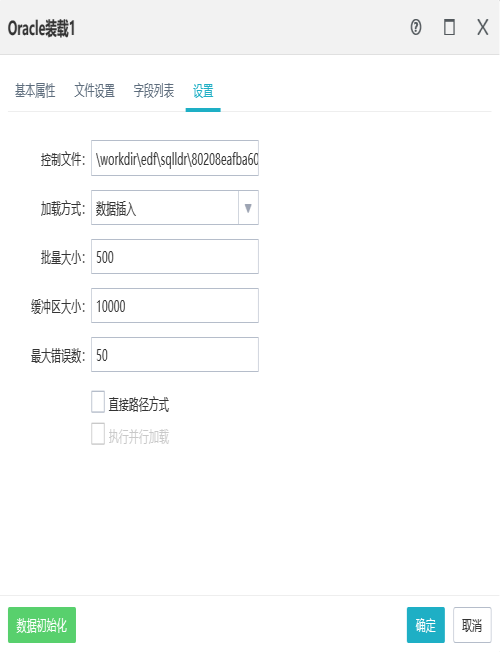
需要设置控制文件、加载方式、批量大小、缓冲区大小和最大错误数,设置直接路径方式。加载方式分为4种:数据插入、数据追加、替换和清空表。
7.转换组件
7.1表达式组件
作用:
通过函数表达式对前置组件各字段的数据进行转换处理,得到新的结果集数据。
按钮说明:
新增 | 在表达式组件中,新增字段 |
删除 | 删除或批量删除字段 |
上移/下移 | 调整字段位置。 |
拾取 | 拾取前置组件的字段 |
文本编辑 | 点击后,切换到文本编辑器,编辑表达式组件字段。再次点击可以返回列表模式 |
查找替换 | 将所有字段属性中的匹配字符串批量替换成指定字符串。 |
示例:
使用表达式组件中的UPPER()函数,将persons表中的firstname和lastname字段内容转化为大写。
实现步骤:
1.如下图新建交换任务
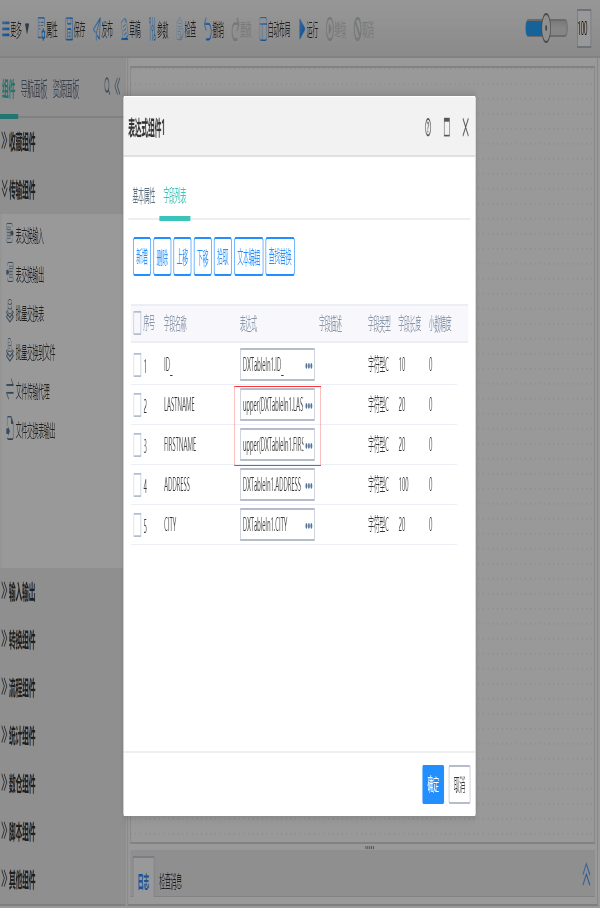
2.设置表达式组件中的firstname和lastname字段表达式,使用UPPER()函数
3.运行后查看结果
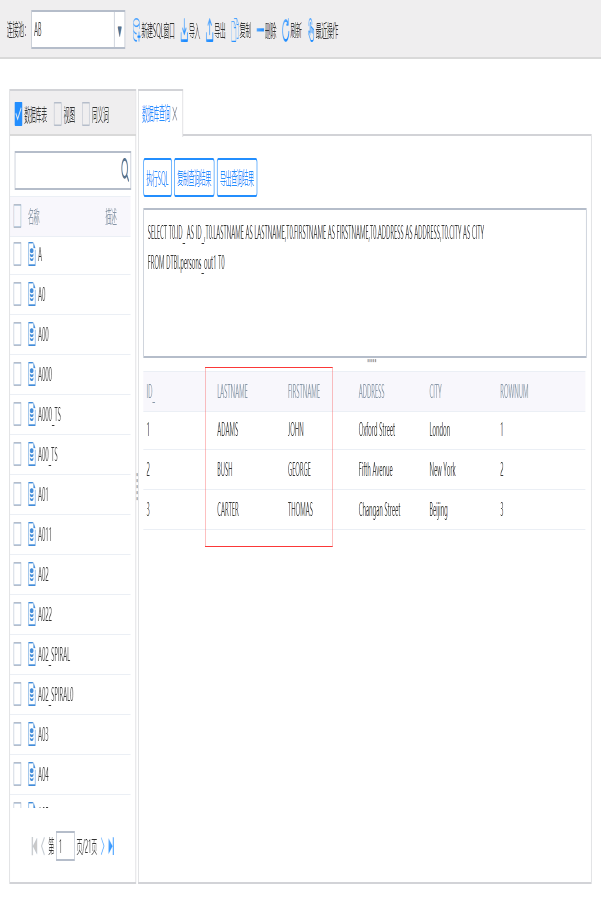
7.2聚合组件
作用:
聚合组件主要完成的是分组聚合功能,将输入的数据进行分组,利用分组函数对数据进行处理,最后将数据写入目标,类似于数据库的GROUP BY操作。当聚合组件连接上前置组件,且前置组件已设定好字段后,聚合组件会出现前置组件的字段信息。
7.3集合组件
作用:
集合组件可以对2个或者多个表结构相同的源数据进行集合运算,支持并集(union&union all)、交集(intersect)、差集(minus)的运算方式。
7.4连接组件
作用:
连接组件用于完成将多个表进行连接,将连接后的结果输出。连接组件的连接方式主要有以下几种:内连接、左连接、右连接、全连接,与数据库里表连接的方式类似,通过确定关联字段和关联条件,最后得到匹配连接后的结果集。连接的输入是两个以上,输出只有一个。
7.5过滤组件
作用:
过滤组件主要完成的过滤功能,在输入数据中进行筛选出需要的结果集合,最后装载到目标中去,类似于数据库的where操作。在确定完源和目标映射字段后,在过滤组件的公式编辑区域可以编辑过滤表达式,完成对输入结果的过滤,满足条件的结果进行输出,过滤组件的输入只有一个,输出可以是多个,对于满足不同条件的结果可以选择输出到不同的结果集中。
过滤组件分为简单过滤和自定义过滤:
简单过滤,可选择前置组件中的部分字段,在定义操作符、取值已经条件连接符后,即可实现过滤。

过滤组件默认使用简单过滤,针对字段类型不同,取值设置方式也不同:
1、字段类型为日期或时间戳时,取值列显示日期下拉框,用于选择日期取值
2、字段类型不是时间或日期时,取值列显示为文本输入框
操作符支持选择:=、<>、<、>、>=、<=、IS NULL 、IS NOT NULL
操作符选择IS NULL 或者 IS NOT NULL 后,取值设置自动置灰
自定义过滤则支持SQL语句,并可通过编辑器对SQL语句进行验证。
7.6排序组件
作用:
可以将前置组件的结果集按字段值升序或降序排列。
7.7清洗组件
作用:
通过多种清洗规则对源数据进行清洗。
在清洗组件中可添加各种清洗规则。

字段级清洗:主要是针对某个字段里面的内容进行相应的处理。
记录级清洗:主要是进行数据过滤。
7.8行更新组件
作用:
行更新组件用于处理行间数据,将某一行的前后几行数据来计算填充某列数据。该组件常用于计算累计行数据。
7.9计算字段组件
作用:
根据条件字段和取值字段设置计算某条记录或某个字段是否输出。

当不勾选有返回参数时,后面可以接其他组件,且界面上不需要设置取值字段、分割符、返回参数,界面上该三项也会为不可设置状态。有返回参数时,后面无须再跟其他组件,因为得到的结果是一个字符串,赋值给了参数,所以后续组件是获取不到任何结果集的。
7.10唯一标识组件
作用:
输入数据新增列唯一标识字段,生成GUID,作为唯一标识,字段名称可编辑,字段类型为字符型。

列名称为必填项,是新添加字段的字段名,默认值为GUID_。列标题可以为空,是新添加字段的表头,列标题默认值为“唯一标识”。
本组件会在输入数据中新添加一列数据,数据类型为字符型。
7.11序号组件
作用:
在输入数据新添加一个序号字段。
序号支持设置起始值,依次递增。
可设置字段类型与长度,类型包括字符串类型和数值类型。
如果为字符型,将根据用户所选的长度,在序号前用0进行补齐,来保证排序。
该组件会在输入数据新添加一列数据。
7.12删除组件
作用:
根据前置组件的结果集来删除指定表的特定数据记录。

连接池、选择表:选择要删除数据的某张表和该表对应的连接池。
选择:点击"选择"弹出字段选择弹框,和表输入的选择功能一样。
字段来源:下拉选择列表,包括前置组件的所有字段名。(用来设置删除数据时和该组件字段的对应关系)
8.流程组件
8.1路由组件
作用:
可以完成对数据的分流,将符合分支条件的多个结果集,输出到多个目标表中。
路由组件必须连接后置组件后,才能进行设置。
默认分支是指,前面的条件都走完了,剩下的会进到默认分支。
8.2分支组件
作用:
可以根据分支条件是否为真,来执行后需的数据交换过程组件,如果结果为true则执行,为false则不执行。
同路由组件一样,分支组件必须连接后置组件后,才能进行设置。
根据分支设置默认的分支条件和后置组件,也可以手动修改分支条件和后置组件。
8.3校验组件
作用:
通过比较记录行数或使用自定义表达式来验证数据交换中的数据或流程。

点击”新增”按钮可以添加校验条件。
9.统计组件
9.1采样组件
作用:
采样组件分成5种:拆分采样,随机采样,基础采样,过采样,指定行采样。
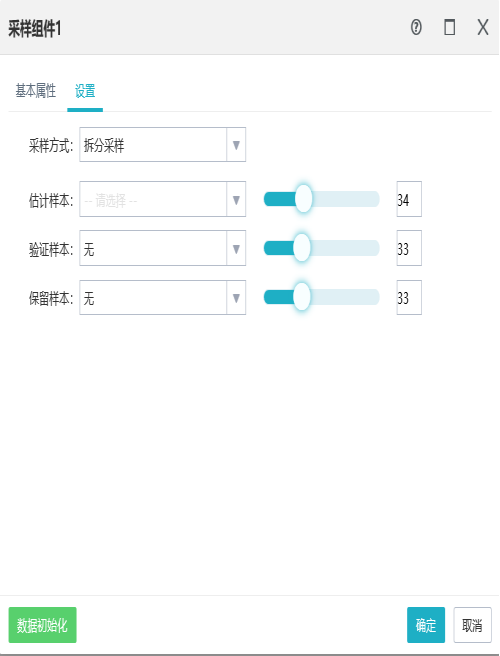
拆分采样:
1)将数据根据百分比分成3份样本,3个百分比之和不能超过100%;
2)估计样本必须设置后置组件,验证样本和保留样本可以不设置;
3)保留样本的数据量为总量减去验证样本和估计样本的数据量;
4)抽取结果为随机抽取,各个样本之间数据不重复。
随机抽样:
1)两种形式:1.固定返回一定数量的记录;2.返回一定占比的记录;
2)通过设置“随机种子”的值来保证每次运行样本的一致性。
基础抽样:
1)抽样方式:
前N个记录:返回表中的记录,直到指定的N记录。
最后N个记录:返回从指定的N记录开始的表中的记录。
跳过第N个记录:返回指定的N个记录之后的所有记录,跳过所有记录,包括N。
每个N记录中的1个:返回每N个记录的第一个记录。
每个记录的随机1在N机会中:随机选择每N个记录的记录。
2)可设置分组字段,如设置了分组字段,则根据上面设置的抽样方式,在分组后的每个数据集中进行采样;
过采样:
1)设置一个字段,基于该字段进行过采样;(该字段值一般都是一个二元值)
2)设置该字段的少类样本值,即样本中该字段值占比较少的值;
3)设置采样百分比,即样本抽取的百分比;
4)采样结果应该是少类样本占抽样出来的样本的一半。
该百分比不得超过少类样本在总样本中的占比一倍,如果用户设置超过一倍,少类样本没有足够数据抽取,则将少类样本全部抽取出来,并按照1:1的比例,抽取多类样本数据,并给出警告信息。即,如果100条数据中,少类样本有5条,用户设置采样比例为20%,则实际抽取为10条数据,5条少类样本和5条多类样本,并给出警告信息,告知用户由于少类数据不能达到抽取比例,所以实际抽取比例为10%。
指定行采样:
-2,含义为小于2,即输出第一行和第二行数据
3,含义为等于3,即输出第三行数据
17-20,含义为17到20之间,即输出17行到20行数据
50+,含义为大于50,即输出50行到最后一行数据
9.2字段统计组件
作用:
根据选择的字段分类统计,统计方法包括:空值、唯一值、最大值、最小值等。
根据字段类型选择不同的统计方法,针对同一个字段也可以选择多个统计方式。

点击”选择”按钮可以批量勾选添加字段,可对每一个字段选择不同的统计方法。
10.数仓组件
10.1维度转换
作用:
将服务器中的层级维转化为通用维,生成一个新的维表。
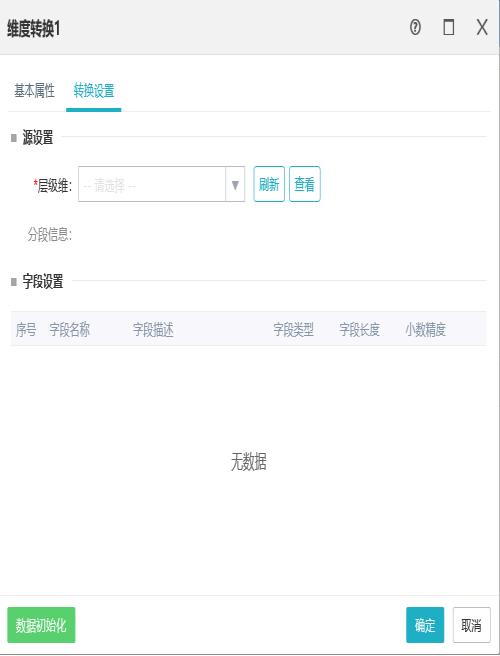
层级维为系统中公共维表和主题域下的所有层级维。点击可更换层级维,原始列HBCODE和HBNAME不可编辑,生成的层级列LEVEL1_ID_等可以自由设置,所有的字段描述都可以编辑。
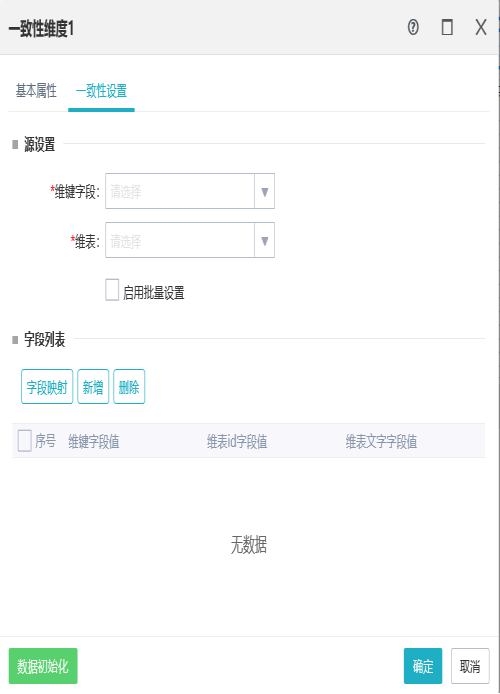
10.2一致性维度
作用:
可以对源数据中的维字段进行统一编码,保证维度的一致性。
可设置字段类型与长度,类型包括字符串类型和数值类型。
如果为字符型,将根据用户所选的长度,在序号前用0进行补齐,来保证排序。
维键字段:来源于前置组件,当一致性维度组件与前置组件连线之后,即可获取前置组件的所有字段。
维表:来源于公共维表或者数据源中的维表。
字段映射:指定字段值与维表id之间的映射关系,并提供3种字段自动对应的方式。
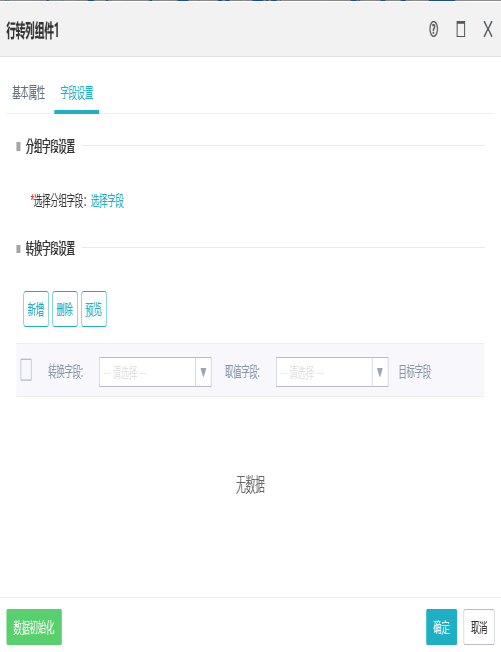
10.3行转列组件
作用:
点击选择字段,可以进行添加修改分组字段,相同字段不能被重复添加
选择转换字段,下方会自动出现转换字段的值,并可通过“新增”“删除”对字段进行编辑。
选择取值字段,会自动根据取值字段_转换值进行命名,可以人工修改。
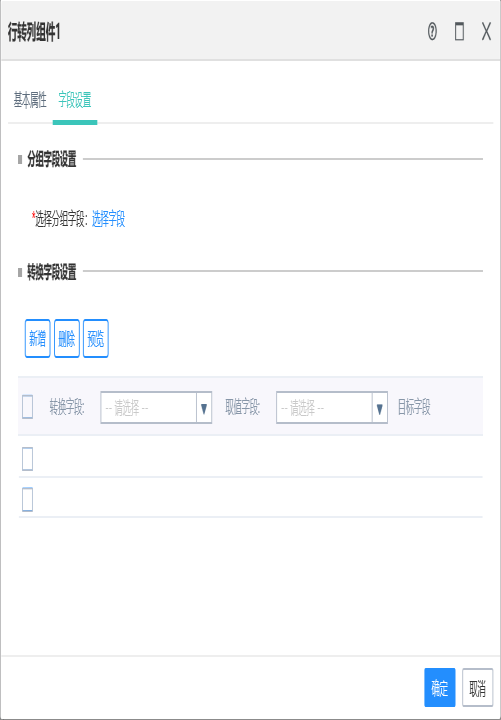
点击预览可以查看效果。
10.4列转行组件
作用:
手动设置转换字段的名称和取值字段的名称,并选择转换字段后,下方会出现转换字段,需要手动设置转换值。
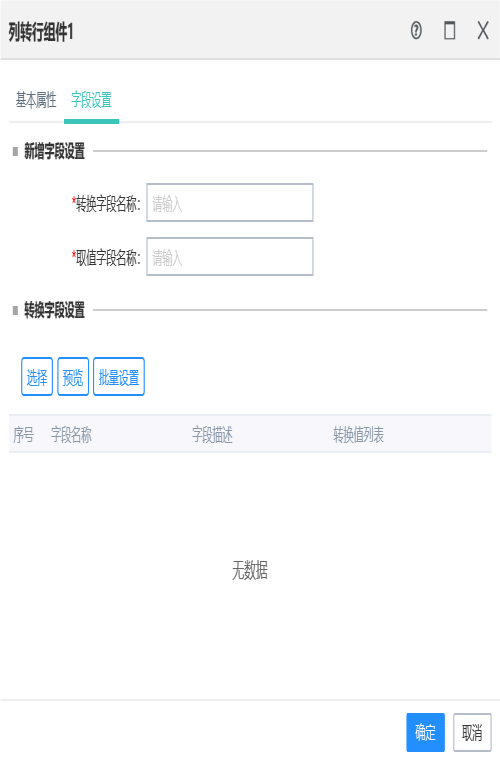
点击预览,可以查看设置的效果。
10.5列转多行组件
作用:
可以将源表中的行记录的某列值,按分隔符的转换多行记录。
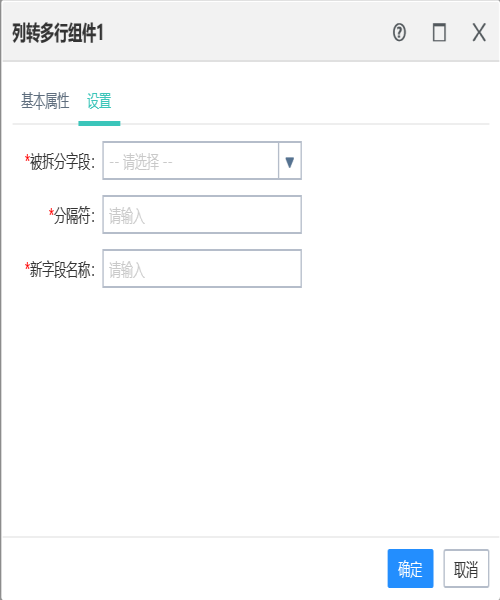
被拆分字段:来源于前置组件的输出字段。
分隔符:拆分字段记录的依据(例如逗号",")。
新字段名称:拆分后的行的字段名。
10.6周期快照
作用:
周期快照以具有规律性的、可预见的时间间隔来记录事实,是发现数据变化规律的重要方式。
周期快照组件是将有缓慢变化的历史表转换成一定间隔周期的表。
基础设置:
1.分组字段可选可不选,分组字段的作用:对周期表结果进行分组查看中间缺失周期进行填充。
2.起始结束字段如果是日期或时间字段,就不需要展示日期格式字段,否则展示。起始结束日期字段可以是日期、时间和字符串类型
3.周期支持年、季度、月、日,统一添加列字段名:periodic_
4.不同周期字段格式参考数据期格式如下:
年: 2014、2015、 2016
季度:201401、 201402、 201403、 201404
月:201401、 201402、 201403、 201404、 201405
日:20140101、20140102。。。
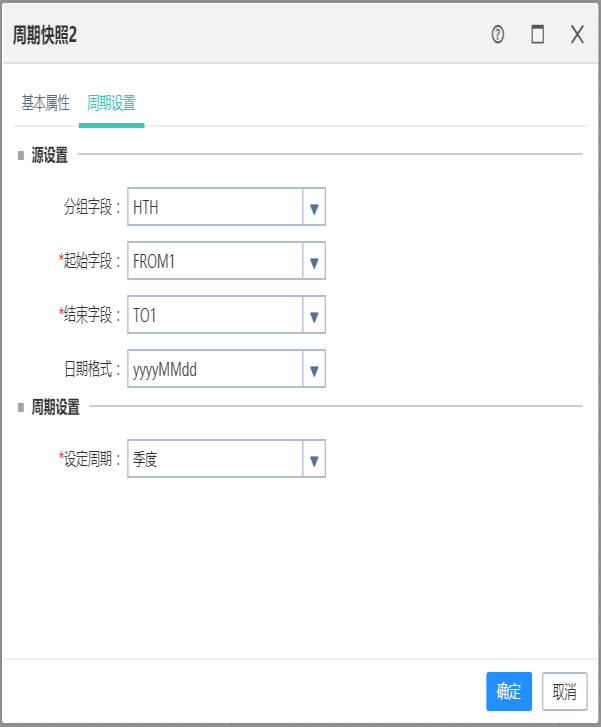
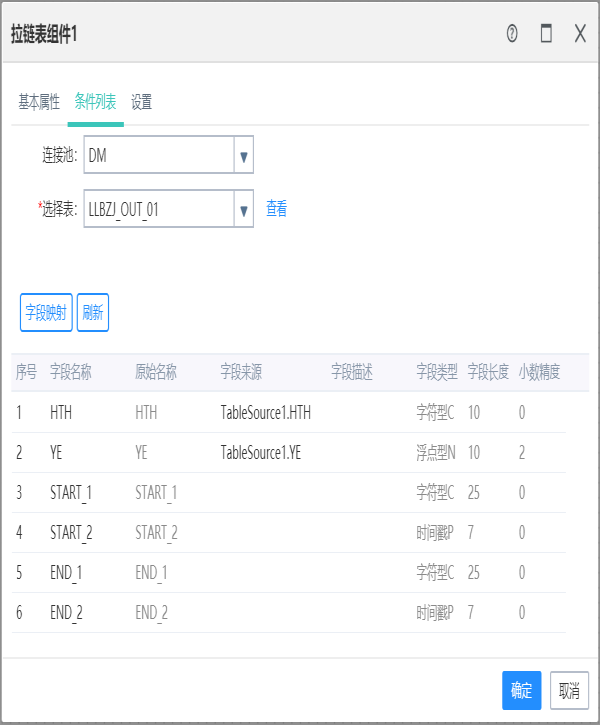
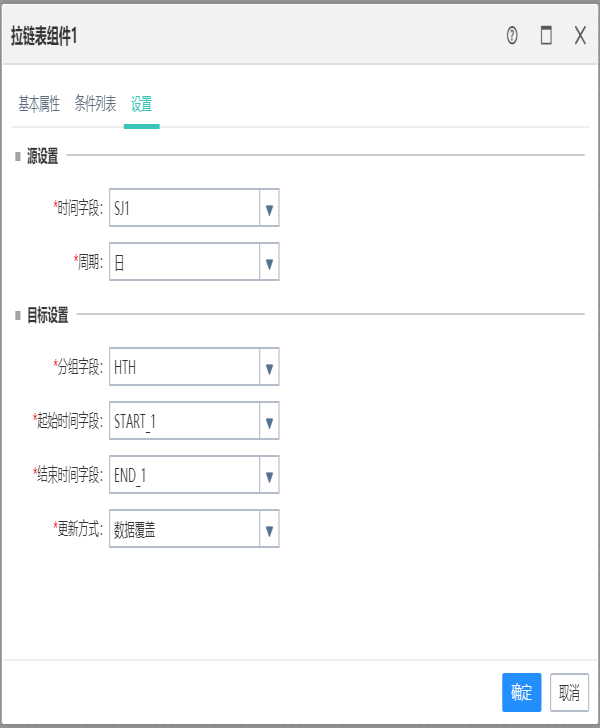
10.7拉链表组件
作用:
将前置输入的周期表转成拉链表,并根据当前组件设置的更新策略插入到当前组件选择的数据库表中。
基础设置:
字段列表界面设置将要入库的表,并在字段映射中设置与输入字段的映射,字段列表的字段名称可以修改;
设置界面中源设置要设置输入的时间字段;
目标设置需要设置当前组件中的起始时间,结束时间字段和分组字段,分组字段可以多选;
更新策略有两种,一种是数据覆盖,会清空目标表,一种是插入更新,有对应的数据则更新,没有则添加;
字段列表页面选择的字段,除了时间字段以外,都要有字段映射。
11.脚本组件
11.1SQL组件
作用:
可以用来在数据交换过程中执行SQL语句,当需要做的数据处理不能使用已有组件完成时,可以选用此组件。
11.2存储过程组件
作用:
可以用来在数据交换过程中调用存储过程做数据处理。

11.3Shell组件
作用:
可以用来在数据交换过程中调用执行Shell命令。

在脚本输入框中输入Shell命令。
12.其他组件
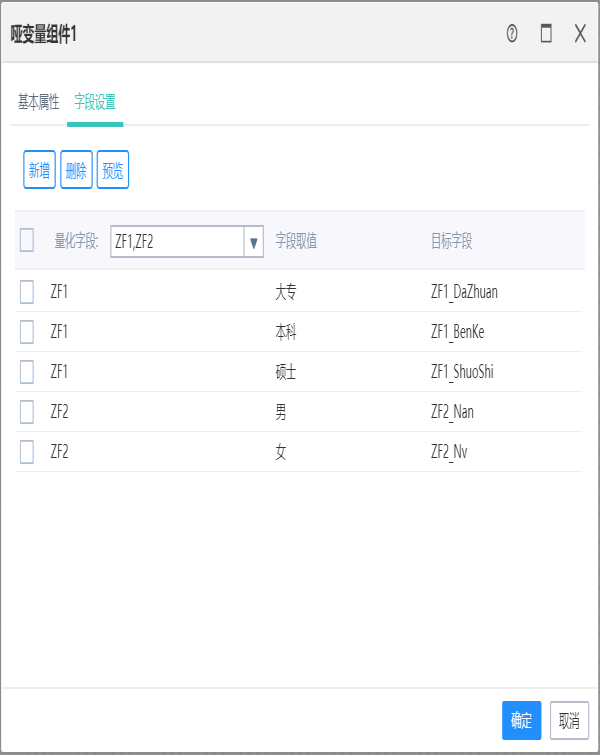
12.1哑变量组件
作用:
将不能定量分析的字符串类型数据,根据它的取值范围,转化为多列的0、 1数值矩阵,方便数据进行下一步的定量。
选择的量化字段只能是字符型,其它的类型没有意义。
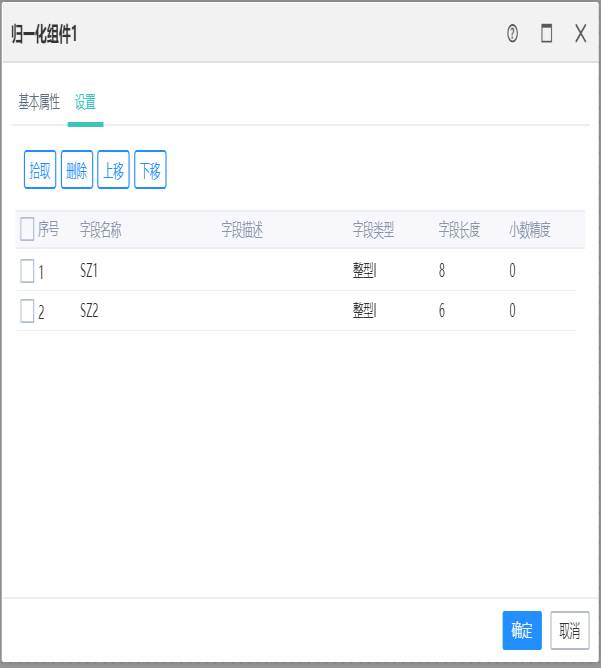
12.2归一化组件
作用:
该组件可以简化计算,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量,便于不同单位或量级的指标能够进行比较和加权,解决数据指标之间的可比性问题。
用于对数值型字段进行处理,处理方式为:新数据=(原数据-最小值)/(最大值-最小值)
处理后的数据

12.3标准化组件
作用:
该组件将数据z-score标准化,经过处理后的数据均值为0,标准差为1,常用于机器学习中,如像素数据的处理。
用于对数值型字段进行处理,处理方式为:新数据=(原数据-均值)/标准差
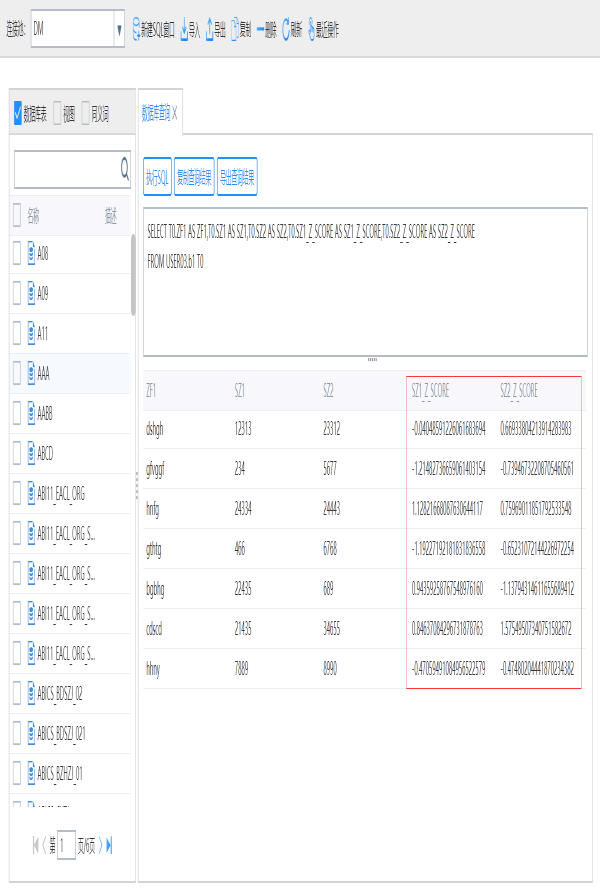
数据处理结果参考
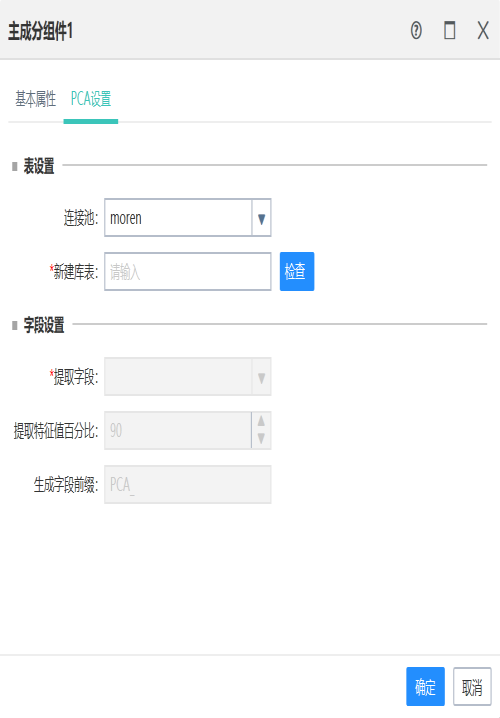
12.4主成分组件
作用:
根据数据库表中选取指定字段来进行PCA计算,所选字段可以是数值型和字符型,当为数值型时,进行的是降维计算;但是当是字符型时,处理方法为把每一条数据当做一个维度来计算。
基础设置:
1.表设置可以选择连接池,新建数据库表名;
2.字段设置只能选择前置字段中的字符型、数值型字段;
3.提取特征值百分比在1~99之间;
4.字段前缀有默认值。
12.5参数赋值组件
作用:
可以在交换任务执行的过程中,改变参数的取值,供后续组件调用参数。
13.接口组件
13.1HTTP接口组件
13.1.1组件作用选择接口数据源下的json格式接口,读取接口返回结果,将结果保存到临时表的一个字段中,供后置组件使用
13.1.2组件设置13.1.2.1接口设置界面
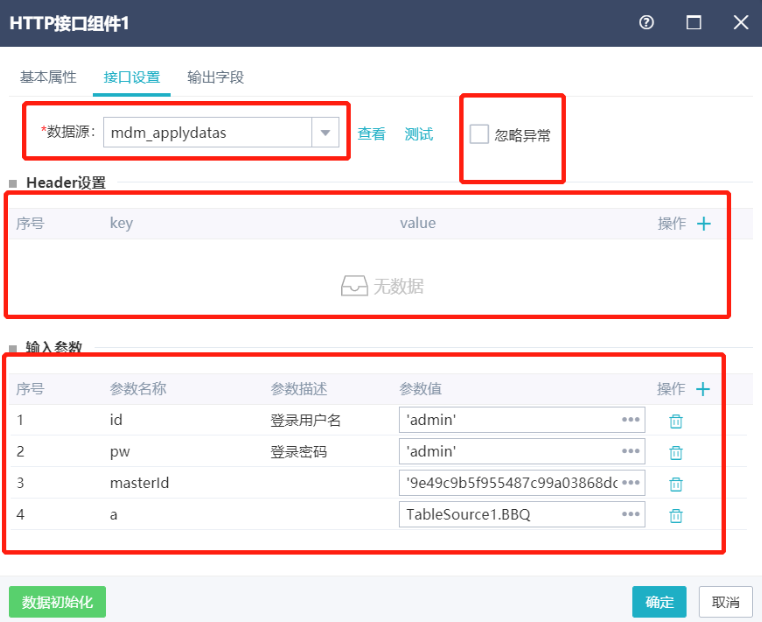
数据源:选择数据源下的一个接口数据源(只支持json格式)
查看:跳转页面到接口数据源列表
测试:查看接口数据源访问返回数据
忽略异常:多用于重复请求的情况,如需请求接口N次,在其中某次请求失败时,会直接报错并终止整个流程,但勾选了忽略异常会跳过失败的请求,继续执行剩余的请求。
header:设置请求头,如token等
参数名称:可以根据需要自行添加
参数值:支持常量、宏以及前置输入组件的字段,参数设置为字段时会读取字段所有取值循环调用接口。
13.1.2.2字段设置界面
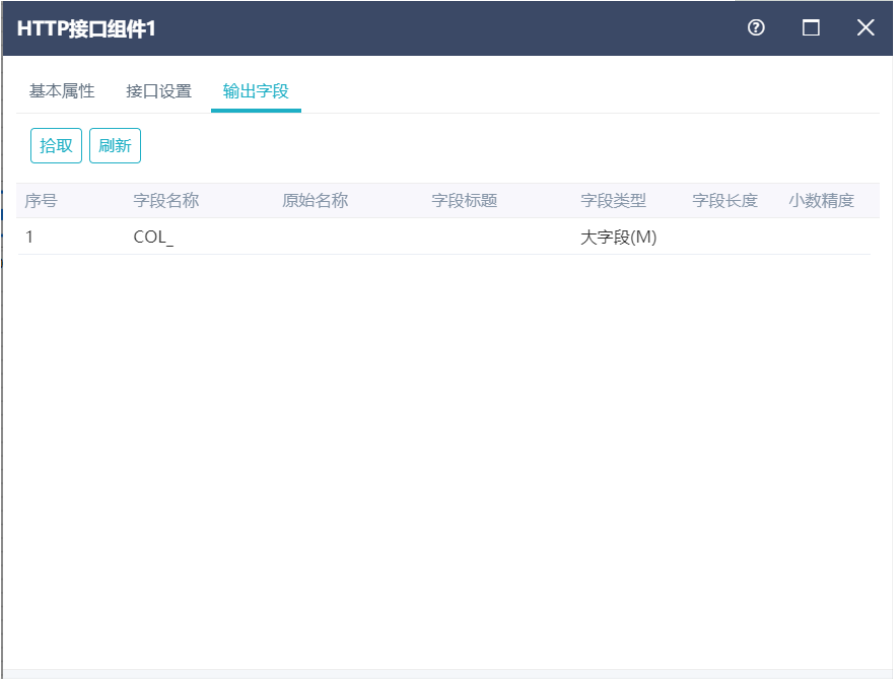
刷新:刷新仅仅只刷新HTTP默认创建的字段COL_,功能为还原字段设置(字段名称,字段类型,字段长度,小树精度)
HTTP接口组件默认自动创建一个定义好的字段(用于保存接口返回结果)
字段名称 | COL_ |
原始名称 | |
字段类型 | 大字段M |
字段长度 | 100 |
小树精度 | 0 |
| 注意: 1、接口返回结果会存储在一个大字段中 2、DB2下CLOB默认存储1M数据,返回结果超过1M时需修改数据库层面配置 |

拾取:当组件的参数值设置选择为前置组件的字段时,可以根据需要拾取前置组件字段,拾取的段的原始名称这一列不允许修改
13.1.3组件例子参数来自前置组件字段值的例子:

前置表输入选取的表有6w多条数据,所以会循环请求6w次接口
| 注意: 1、请求接口的实际用时与请求的次数,当时网络状况,系统配置,接口并发大小等多种因素相关,具体耗时需要自行测试,耗时过长时请自行先排查 2、有些接口存在请求次数限制,如:每分钟最多请求100次,则需要分批次请求接口 |

1.该组件的输出字段列表来自本组件的字段列表。
2.该组件没有对应的实体表,用临时表代替,所以只能在调试模式下预览数据。
3.该组件可以没有前置组件
4.数据源设置时,记录调用日志功能如果勾上的话,同时可以配置请求成功条件(edataexchange123及之后版本有此功能),请求成功条件采用的是json格式,用于匹配接口返回中是否有对应的key值,再根据对比对应的value判断是是否请求成功,如果成功条件为空,默认请求成功。
5.系统设置中接口日志展示如下:
系统设置日志下新增即接口请求日志,用来记录接口请求的主要信息
列表包括:请求时间,操作,资源ID,接口名称,调用名称(调用任务名),请求header,请求参数,请求状态,登录名称,登录IP,请求结果
该页面默认未展示,需要在war工程中配置
resource.xml中日志节点下增加子节点
<resource id="ELOG$2$EDSO_APILOG" caption="接口请求日志" img=""></resource>
13.2JSON解析组件
JSON解析组件可以将一个JSON解析成数据库表。
json来源:支持来源于前置组件的字段和文件。
字段:选择一个输入字段,该字段的内容作为json来解析。
文件路径:平台所在主机中json文件路径。
父级属性名:父级属性名可以为空,也可以输入一个属性名,也可以输入一个路径(如:data/person/neme)。
对于:{'a': {'a':{'a':1}}}
父级属性名为空时解析为'a'={'a':{'a':1}};
为属性a时解析为'a'={'a':1};
解析节点类型:分为对象和数组,json文件中带有[],可以选择数组

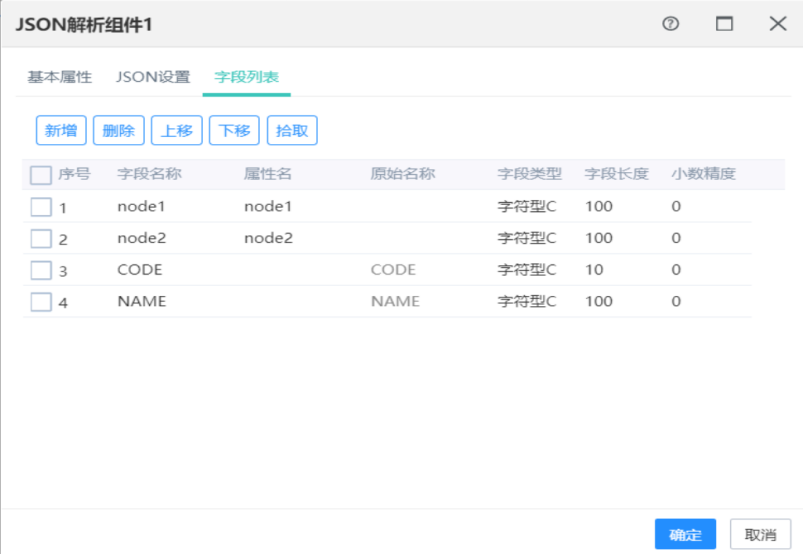
字段列表界面:
可以新增字段,只能新增要从json中解析的字段,然后手动输入字段信息,也可以拾取输入字段。
本组件的输出字段为字段列表中的所有字段,新增的字段只有属性名,没有原始名称,属性名对应json中的属性名。拾取的字段只有原始名称,没有属性名,原始名称对应输入字段名。
注意:在添加字段时,字段名称不要设置为数据库的关键字,否则运行时会报错:缺失表达式
例1:json格式如下,需要解析所有字段的内容。
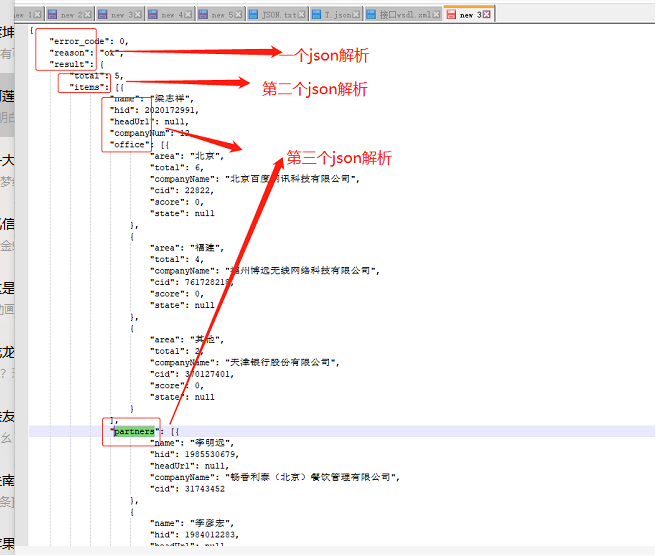
方法:先用第一json解析组件来解析顶级节点的内容,添加顶级节点的字段如error_code、reason、result_(将result节点下的字内容放在一个在一个字段中),然后连接第二个json解析组件,选择存放result子节点的字段,来进行解析第二个子节点的内容,添加第二个子节点的字段如:total、items(将items节点下的字段内容放在一个字段中),同时在字段列表中需要将第一个json解析组件中的所有字段添加上,然后重复添加第三个json解析组件,解析items节点下的内容,同时记得将第二个json解析组件中的所有字段添加上,这样就可以解析到带有层层嵌套的json格式内容的所有字段。如下图:
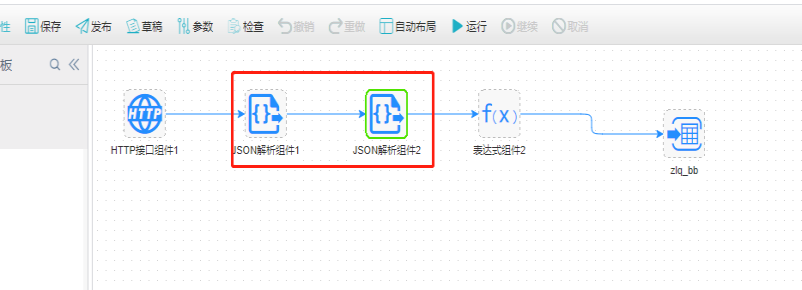
例2:
假如有这样一个json:

values的值是一个数组,数组内的每个元素又是一个数组。
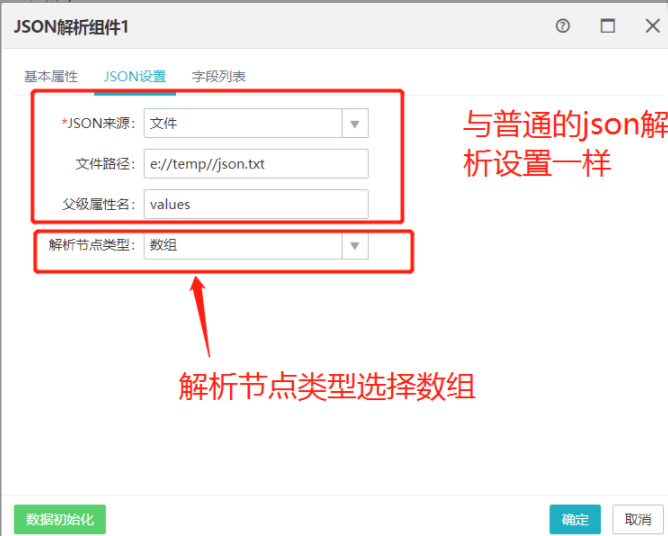
在json设置界面,json来源,文件路径,父级属性名与普通的json设置一样。在解析节点类型中选择数组。
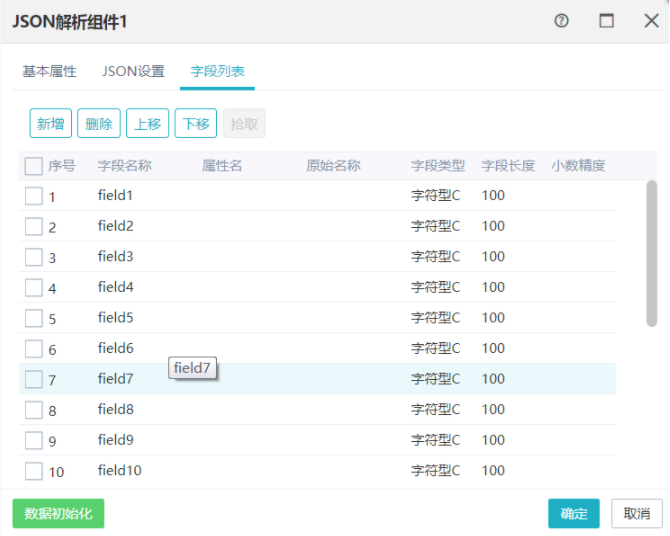
在字段列表界面,和普通的json的解析设置一样添加字段。但是不需要写属性名。
运行之后解析出来的数据:

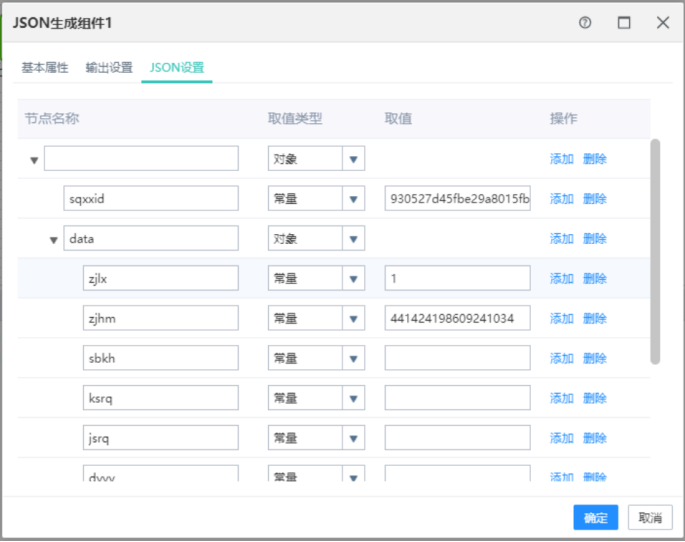
13.3JSON生成组件
根据界面设置,生成一个JSON串。
输出设置页面
输出类型:一般默认选择“字段”,目前只支持字段类型。
字段名:填写输出字段名。
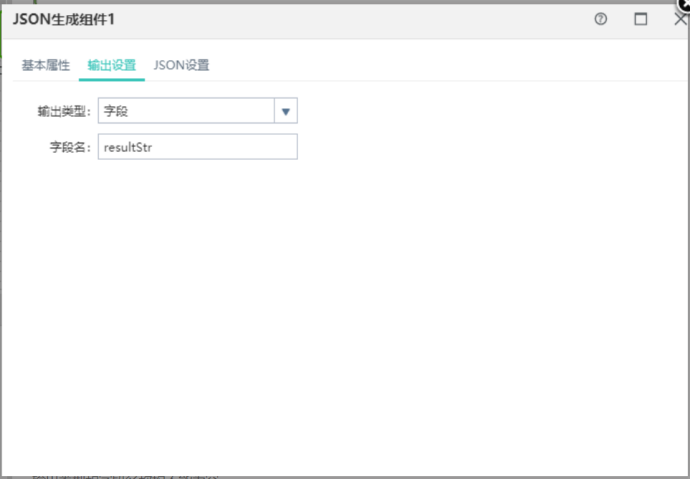
json设置界面:
取值类型有对象,数组,字段和常量四种,对象和数组不允许取值,数组下面只允许存在对象,并且节点名称为空。
13.4WebService接口组件
13.4.1组件作用选择接口数据源下的WSDL格式接口,读取接口返回结果,将结果保存到临时表的一个字段中,供后置组件使用
13.4.2组件设置13.4.2.1接口设置界面
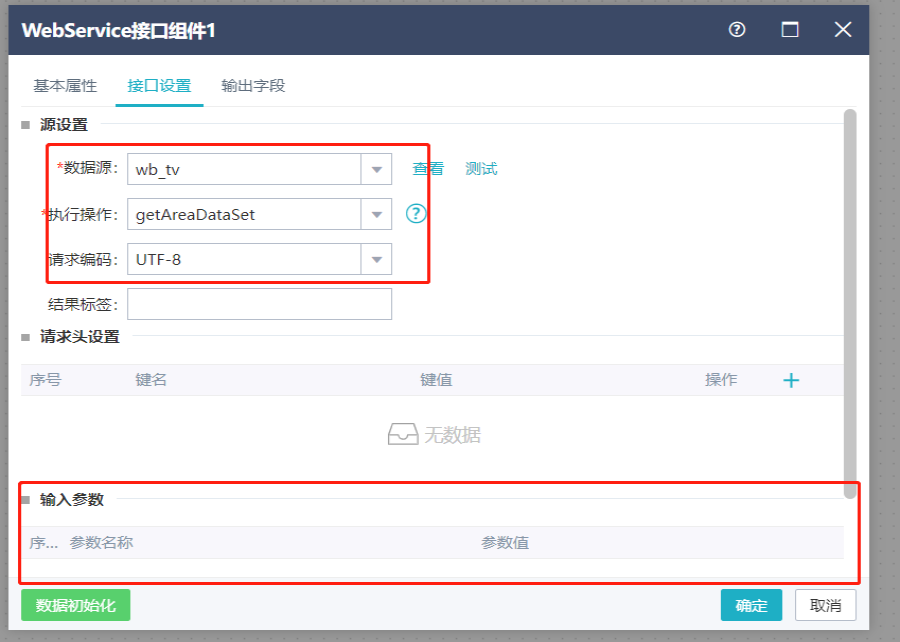
数据源:选择数据源下的一个接口数据源(只支持WSDL格式)
查看:跳转页面到接口数据源列表
测试:查看接口数据源访问返回数据
执行操作:根据所选择的接口数据源自动获取执行操作
请求编码:支持UTF-8和GBK
结果标签:返回报文中结果所在的节点标签
header:设置请求头,如token等
参数名称:选择执行操作之后,自动带出相关参数
参数值:支持常量、宏以及前置输入组件的字段,参数设置为字段时会读取字段所有取值循环调用接口。
13.4.2.2字段设置界面

刷新:刷新仅仅只刷新默认创建的字段RESULT_,功能为还原字段设置(字段名称,字段类型,字段长度,小数精度)
拾取:当组件的参数值设置选择为前置组件的字段时,可以根据需要拾取前置组件字段,拾取的段的原始名称这一列不允许修改
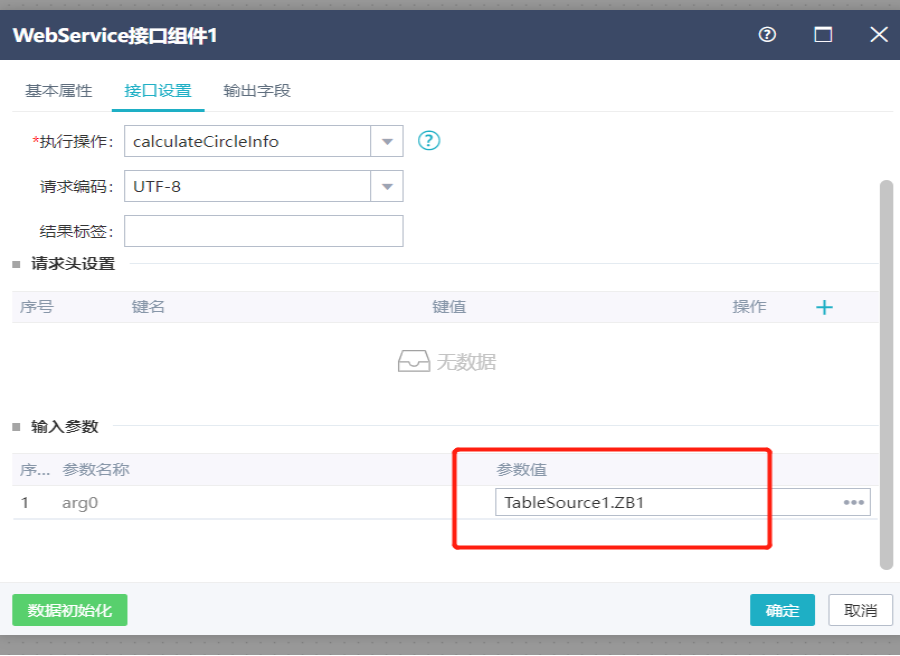
13.4.3组件例子
参数来自前置组件字段值的例子:
13.5XML解析组件
xml解析组件可以将一个xml文档解析成数据库表。
xml来源:可以选择xml文件或者前置组件的字段作为xml的来源。
文件路径:当xml来源为xml文件时,需要填此项,写具体路径,如e://temp/111.xml
字段:当xml来源为输入字段时,需要选择此项,选择一个输入字段,会自动解析字段内容生成xml文档。
解析节点:可选择节点属性值或者节点值,选择节点属性,将解析<>里面的内容,若选择节点值,将解析<a>name="张三”</a>中间的值。

字段列表界面:
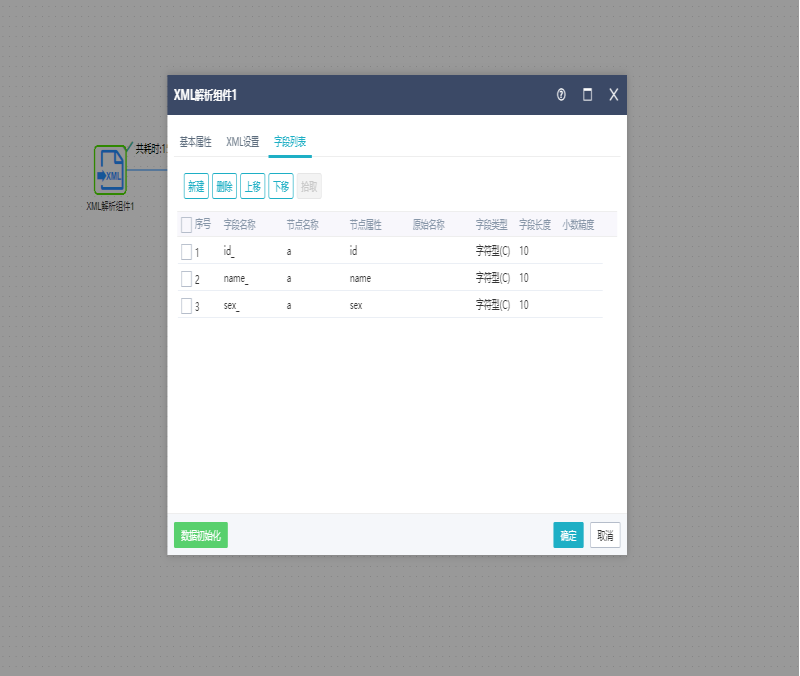
字段名称:创建库表时的字段名。
节点名称:要从从xml中解析的节点。
节点属性:如果节点名称相同,则根据属性来解析指定的节点。节点属性可以为空,为空时解析第一个与节点名称相同的节点。
写法:属性名=属性值。其中属性值可以用英文的单引号或双引号引起来,也可以不用引号。如name=esen,name="esen",name='esen',这三种写法都可以。多个属性之间用逗号分隔,如:name=esen,age=10
原始名称:只有拾取的字段才有原始名称。原始名称与组件输入字段的名称。

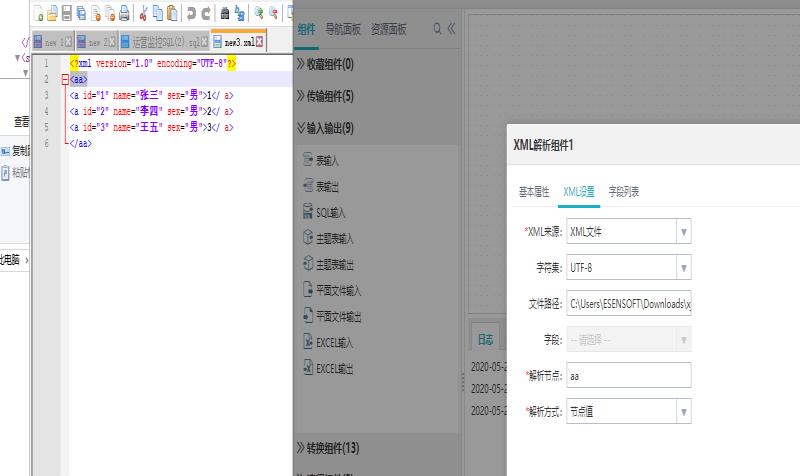
例子1:解析节点为节点属性值,xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<aa>
<a id="1" name="张三" sex="男">1</ a>
<a id="2" name="李四" sex="男">2</ a>
<a id="3" name="王五" sex="男">3</ a>
</aa>
xml设置如下图所示:
字段列表设置,字段名称是可以随意添加(不要设置为数据库的关键字),节点名、节点属性根据xml中节点内容设置,具体如下图所示:
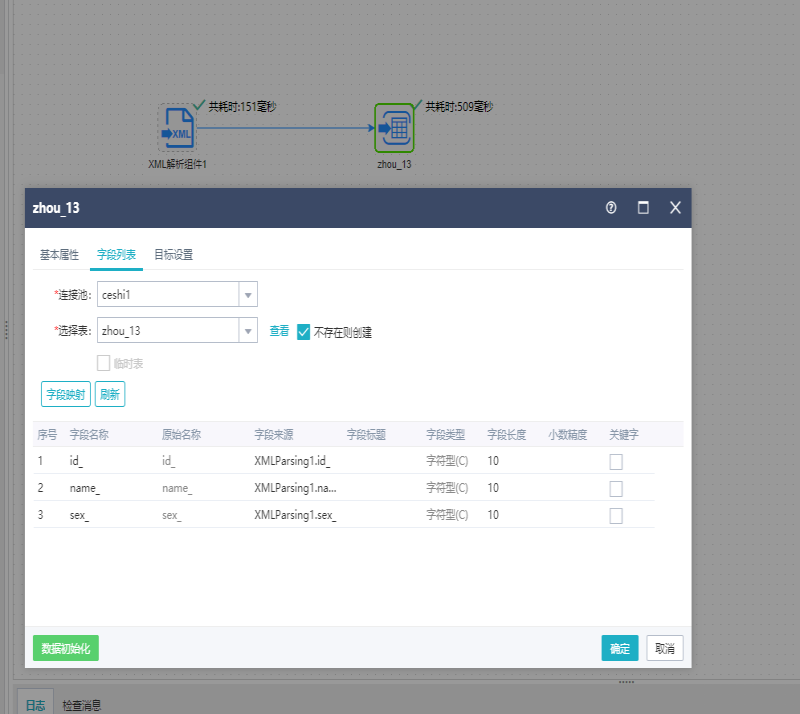
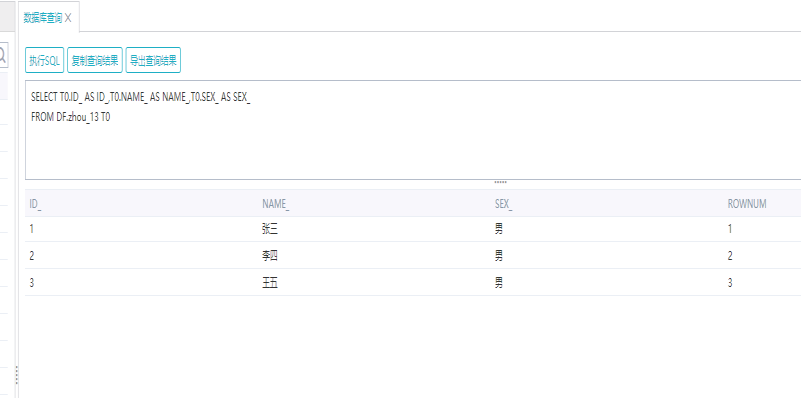
连接表输出组件,将数据存入库表中,在预览数据,如下图所示:
13.6XML生成组件
通过XML生成组件生成想要的xml格式,可接收前置组件传递的数据。
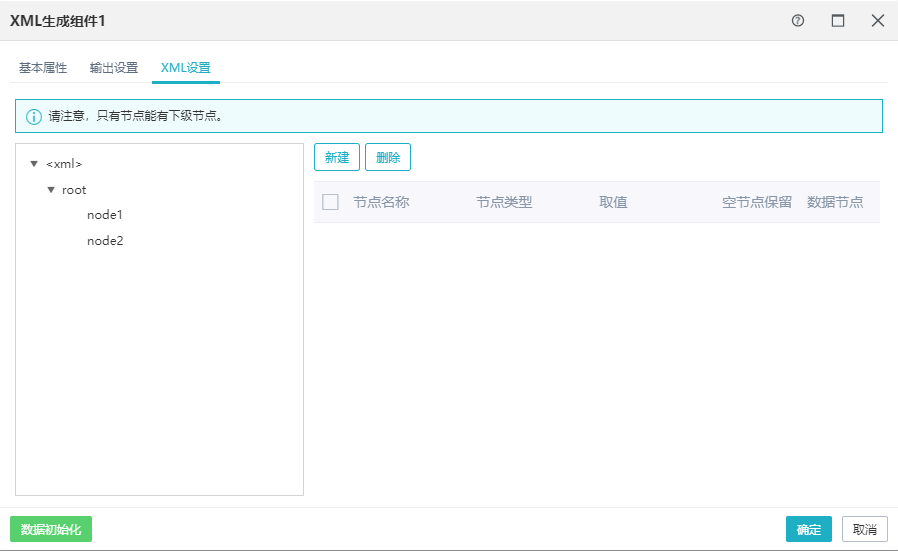
根据“输出设置”生成xml,“xml设置”设置输出内容。
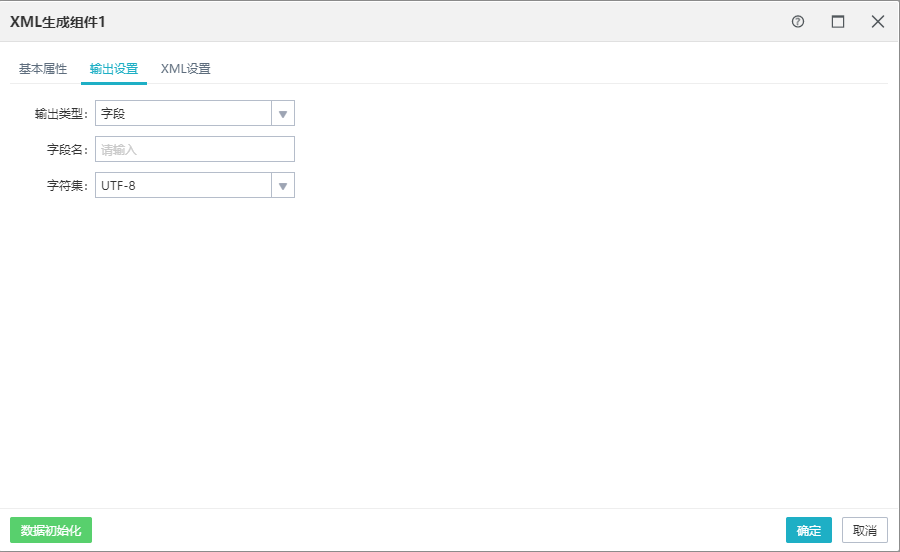
输出类型:一般默认选择“字段”,目前只支持“字段”类型。
字段名:填写输出字段名。
字符集:默认选择"UTF-8",目前只支持"UTF-8"和"GBK"类型。
注意:
a、组件应该有且仅有一个输入组件;
b、xml设置均不能为空;
c、目前只支持输出到字段,取值为字段时,取当前行的值;
d、到文件时(目前不支持),设置数据节点,表示当前节点会进行重复生成,每一条数据会生成一次子结构
13.7质检方案组件
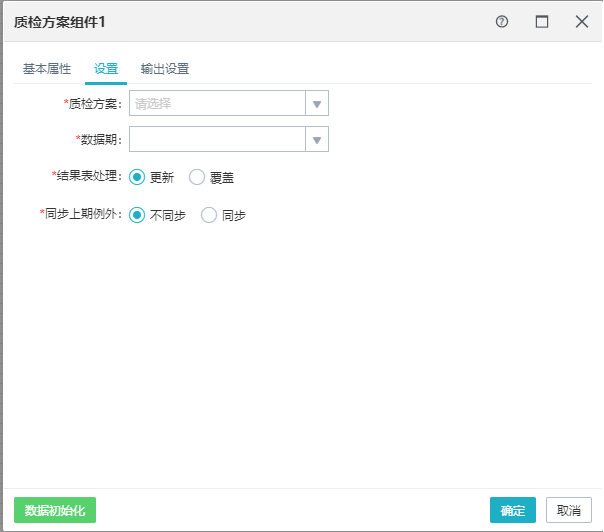
该组件调用并执行指定的质检方案,支持传递质检参数,将质检结果表传递至后置组件。
质检方案:选择相应的质检方案。
数据期:选择相应的数据期,必填项。
结果表处理:更新或是覆盖。
同步上期例外:同步/不同步。
14.文件传输组件
14.1FTP上传组件
作用:将本地文件(夹)上传到FTP服务器(在数据源添加),支持追加、覆盖以及恢复三种模式,
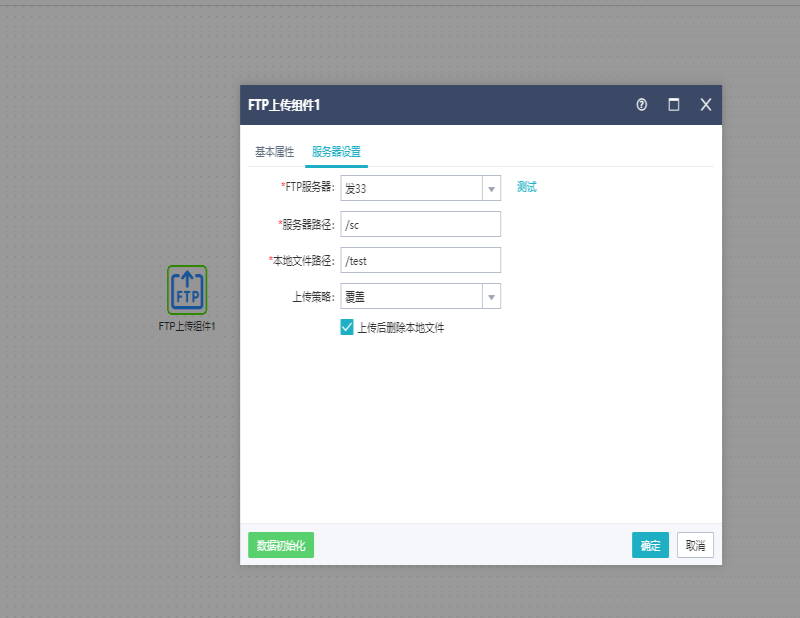
FTP服务器:需要在数据源FTP服务器中新建,这里下拉框中选择已有的FTP服务器。
服务器路径:FTP服务器上的路径。
本地文件路径:指应用服务器所在的主机上的文件路径,可以上传文件夹也,同时支持正则表达式写法
注意:
1、路径中的上下级必须以/分隔;
2、跟目录必须是路径中根目录;
3、支持宏表达式和正则表达式宏表达例如:<#=today()#>获取当天时间、<#=od(today(),”d-1”)#>获取前天时间
正则表达式:正则表达式必须用<>包裹起来,路径中可以有多处正则表达式,但每个正则表达式必须占据一整个目录层级。
如:(以windows为例,兼容linux)
E盘下所有以20191218开头的PDF
文件 E:/<^20191218.*pdf$>
E盘下20191118和20191218两个目录下的所有的excel文件
E:/<2019(11|12)18>/<(?i).*(xls|xlsx)$>
^表示以什么开头;.表示匹配任何字符; *表示示匹配前面字符的任意个数?i表示可以匹配任意字母大小写
14.2FTP下载组件
作用:将FTP服务器上的文件下载至本地(指的平台所在的主机)

FTP服务器:需要在数据源FTP服务器中新建,这里下拉框中选择已有的FTP服务器。
源文件(夹):指的FTP服务器中的下载文件路径,这里支持正则表达式和宏表达式。
目标文件夹:指的平台所在主机的路径
注意:
1、路径中的上下级必须以/分隔;
2、跟目录必须是路径中根目录;
3、支持宏表达式和正则表达式宏表达例如:<#=today()#>获取当天时间、<#=od(today(),”d-1”)#>获取前天时间
正则表达式:正则表达式必须用<>包裹起来,路径中可以有多处正则表达式,但每个正则表达式必须占据一整个目录层级。
如:(以windows为例,兼容linux)
E盘下所有以20191218开头的PDF
文件 E:/<^20191218.*pdf$>
E盘下20191118和20191218两个目录下的所有的excel文件
E:/<2019(11|12)18>/<(?i).*(xls|xlsx)$>
^表示以什么开头;.表示匹配任何字符; *表示示匹配前面字符的任意个数?i表示可以匹配任意字母大小写
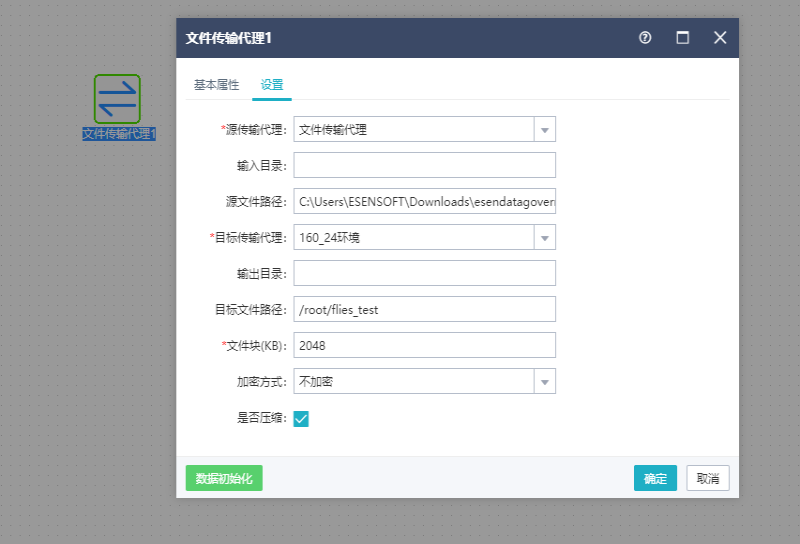
14.3文件传输代理组件
作用:文件传输代理组件可以实现将文件从源传输到目的。
功能介绍:
1.可以选择传输文件块大小;
2.可以选择加密或者不加密,目前加密方式有异位加密;
3.可以选择是否压缩。
1.文件传输代理组件的传输代理在新建的时候都会指定输入目录与输出目录,这里的输入输出目录都是从代理那里读出来的,不能手动输入;
2.目标文件路径与源文件路径说明:
1)使用相对路径是基于传输代理设置的输入/输出目录;
2)使用绝对路径则以绝对路径为准,不考虑传输代理设置的输入/输出目录设置;
3)输入(输出)目录与源(目标)文件路径,二选一,点击确定按钮会检查。
3.组件可以成功运行要保证两个代理可以连接,文件传输代理。
15.大数据组件
15.1Hadoop文件输入组件
本章节主要介绍了需要做数据交换的数据如何进行Hadoop输入操作。
15.1.1前提条件用户已部署HDFS服务器。
15.1.2应用场景用户可以通过Hadoop文件输入组件将大数据库impala或petabase等库中的数据保存到系统数据库中,和表输入组件一样作为输入端。
15.1.3操作步骤操作入口:【任务管理>任务定义>新建批处理任务>大数据组件】
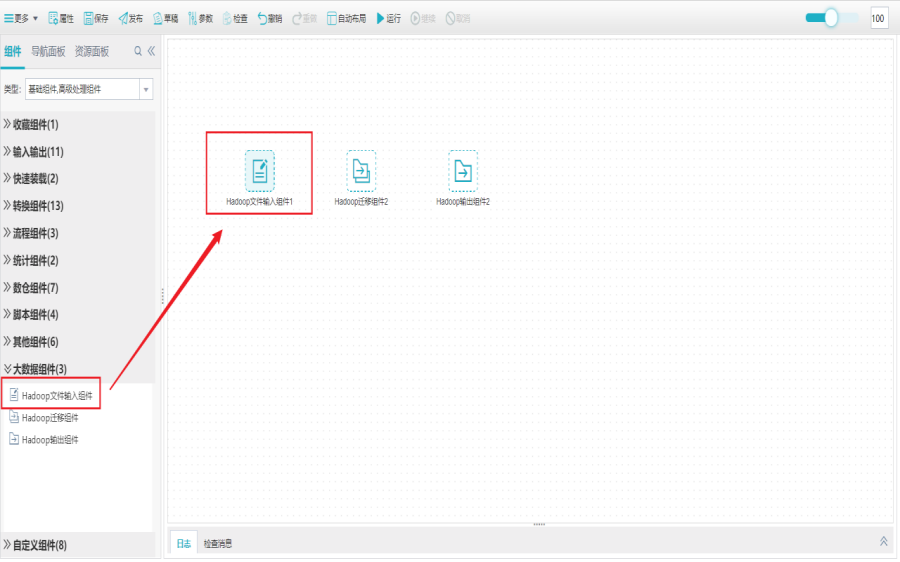
1)新建Hadoop文件输入组件
打开任务编辑器,左侧组件面板中找到大数据分组栏,选择Hadoop文件输入组件拖拽到右边编辑区域。
2)界面设置
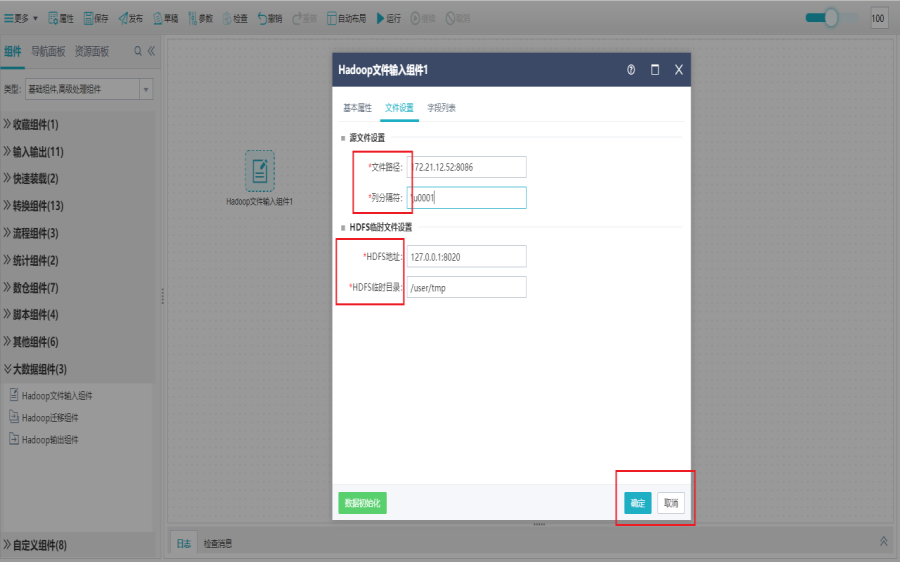
双击Hadoop文件输入组件,打开文件设置界面,设置源文件路径等。
切换到字段列表界面,选择库表,点击确定。

界面设置说明:
HDFS地址:目的连接池所在服务器上的HDFS对应地址,默认是127.0.0.1:8020。
HDFS临时目录:指定源表的数据写入到hdfs上时的临时目录,如果是不存在的目录(因为最终在目标库中生成表时,会将该数据文件从临时目录下移到表数据文件在系统中的默认路径下,一般默认是/user/tmp)
选择表:选择表可以支持下拉选择,也可以手工录入。手工录入时,需要勾选"不存在则创建",会将前置组件的字段列表当做该组件的的字段。
数据写入时覆盖:该选项对已存在的表生效。勾选,则会覆盖已经存在的数据;否则,只是简单的追加,不做重复性校验。
字段映射:设置同表输出组件。
列分隔符:按该分隔符来读取字段列表及字段值,取文件中的列分割符,以该字符对应的十六进制码表示,如\u0001表示不可见字符,\u0009表示tab
15.2Hadoop迁移组件
本章节主要介绍了如何设置Hadoop迁移组件将数据库中的数据批量导入到impala或petabase、hive等库中。
15.2.1前提条件用户已部署HDFS服务器。
15.2.2应用场景用户可以通过Hadoop迁移组件将关系型数据库中的数据批量导入到impala或petabase、hive等库中。
15.2.3操作步骤操作入口:【任务管理>任务定义>新建批处理任务>大数据组件】
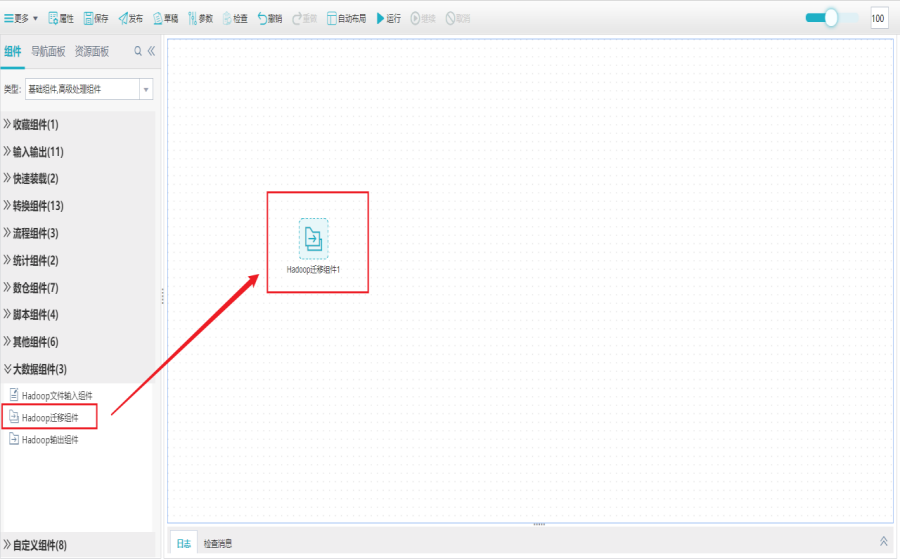
1)新建Hadoop迁移组件
打开任务编辑器,左侧组件面板中找到大数据分组栏,选择Hadoop迁移组件拖拽到右边编辑区域。
2)界面设置
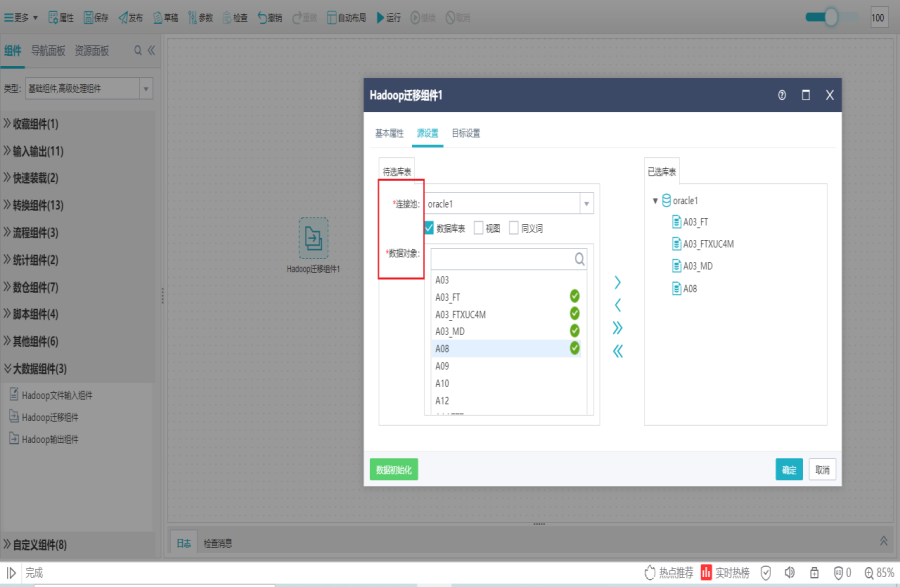
双击Hadoop迁移组件,打开源设置界面,选择源库表。
切换到目标设置界面,设置组件信息,点击确定。
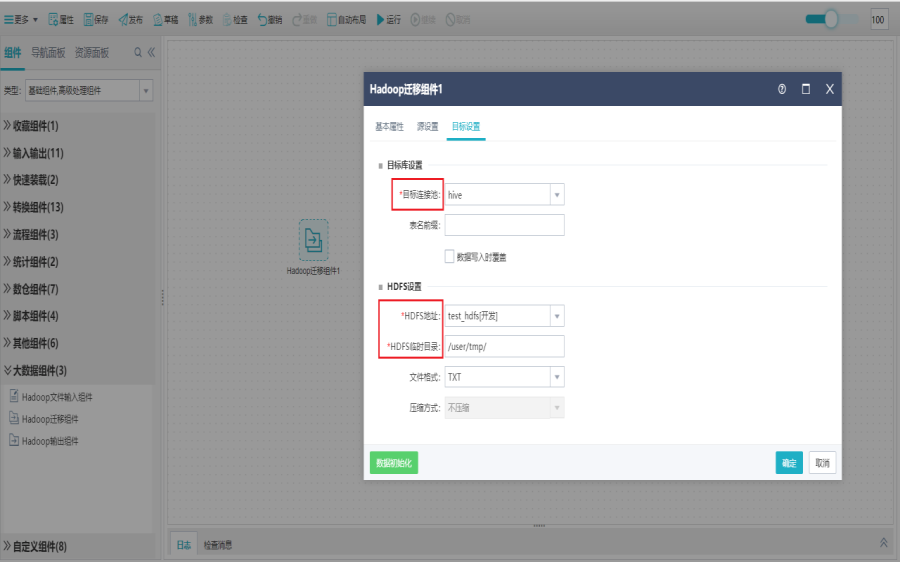
界面设置说明:
目标连接池:只列出impala或hive类型的库。
表名前缀:源表迁移到目标连接池时所生成的表名前缀。
数据写入时覆盖:该选项对已存在的表生效。勾选,则会覆盖已经存在的数据;否则,只是简单的追加,不做重复性校验。
HDFS地址:目的连接池所在服务器上的HDFS对应地址,默认是127.0.0.1:8020。
HDFS临时目录:指定源表的数据写入到hdfs上时的临时目录,如果是不存在的目录(因为最终在目标库中生成表时,会将该数据文件从临时目录下移到表数据文件在系统中的默认路径下,一般默认是/user/tmp)
文件格式:支持TXT和PARQUET两种格式,TDH环境只支持TXT方式,其他环境:如CDH,则使用PARQUET。
压缩方式:TXT文件默认不压缩,PARQUET文件支持几种常用的压缩方式:不压缩(默认)、SNAPPY、GZIP。
注:1.因为HDFS文件的操作涉及到权限的问题,所以对于HDFS临时目录的选择需要注意,如果在组件执行过程中报权限的错(Permission denied),需要修改目录(该目录的权限最好为777)。
对权限的理解详参考:
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_permissions_guide.html
以及http://www.cnblogs.com/webnote/p/5734714.html
2.HDFS临时目录可以指定一个不存在的目录,系统会自动创建该目录。但因为子目录的权限会继承父目录的权限,且由于上述所述权限问题,故最好满足父目录的权限为777。
15.3Hadoop输出组件
本章节主要介绍了经过数据交换的数据如何进行Hadoop输出操作。
15.3.1前提条件用户已部署HDFS服务器。
15.3.2应用场景将经过数据交换etl处理后的数据保存到大数据库impala或petabase等库中,和表输出组件一样作为输出端。
用户使用Hadoop输出组件,选择Hive和对应的表并选择不存在则创建选项,勾选分区选择分区字段,也可以勾选分桶并选择分桶字段、排序字段,点击保存,执行时,自动创建表分区分桶。
15.3.3操作步骤操作入口:【任务管理>任务定义>新建批处理任务>大数据组件】
Hadoop输出组件中支持本地文件快速写入
1)新建Hadoop输出组件
打开任务编辑器,左侧组件面板中找到大数据分组栏,选择Hadoop输出组件拖拽到右边编辑区域。
2)界面设置
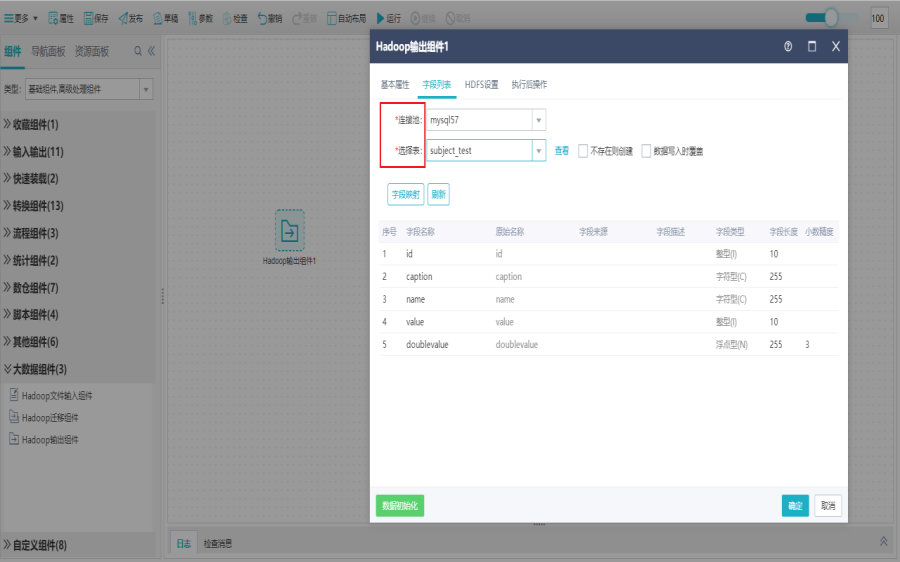
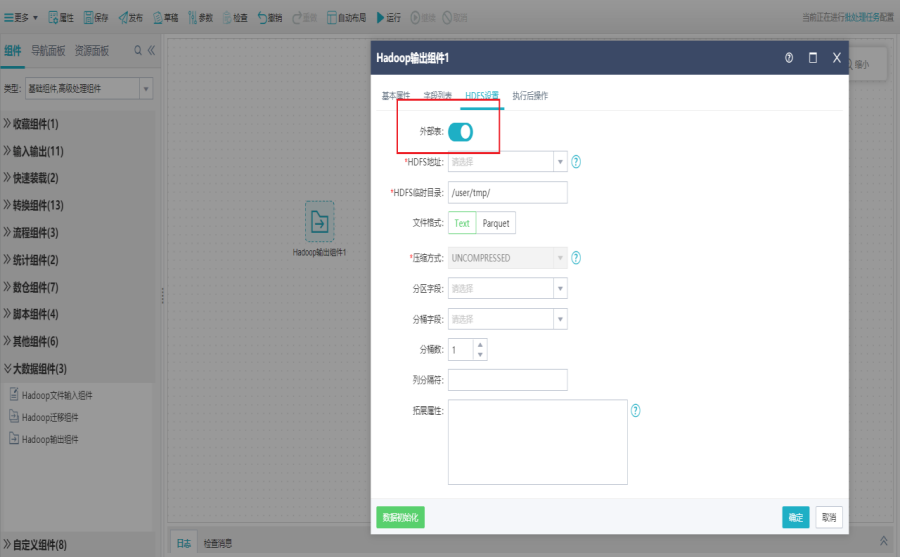
双击Hadoop输出组件,打开字段列表界面,选择源库表。
切换到HDFS设置界面,填写设置信息,点击确定。
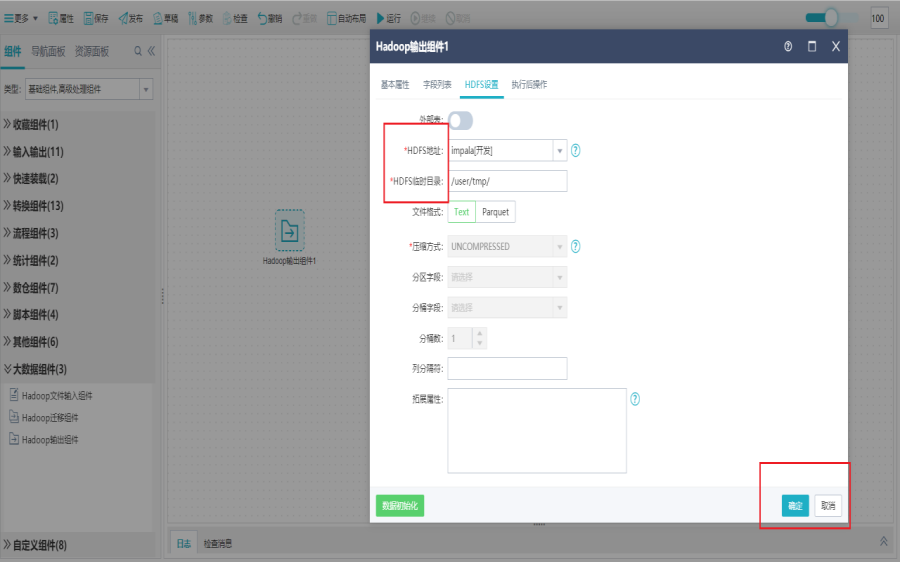
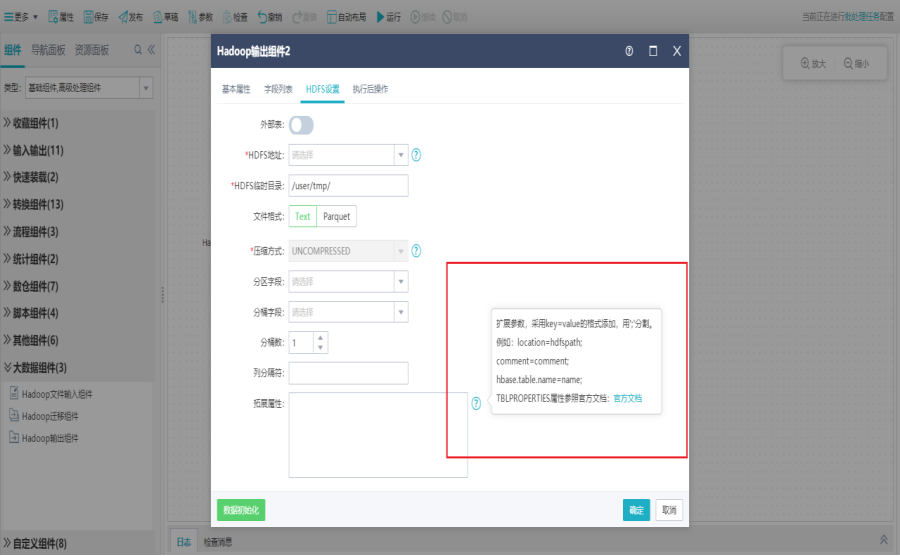
Hadoop输出组件也支持扩展属性配置,如:表格式,编码等,可点击官方文档进行参考。
HDFS设置说明:
HDFS地址:目的连接池所在服务器上的HDFS对应地址,默认是127.0.0.1:8020
HDFS临时目录:指定源表的数据写入到hdfs上时的临时目录,如果是不存在的目录(因为最终在目标库中生成表时,会将该数据文件从临时目录下移到表数据文件在系统中的默认路径下,一般默认是/user/tmp)
文件格式:支持TXT和PARQUET两种格式,TDH环境只支持TXT方式,其他环境:如CDH,则使用PARQUET
压缩方式:TXT文件默认不压缩,PARQUET文件支持几种常用的压缩方式:不压缩(默认)、SNAPPY、GZIP
列分隔符:按该分隔符来读取字段列表及字段值,取文件中的列分割符,以该字符对应的十六进制码表示,如\u0001表示不可见字符,\u0009表示tab
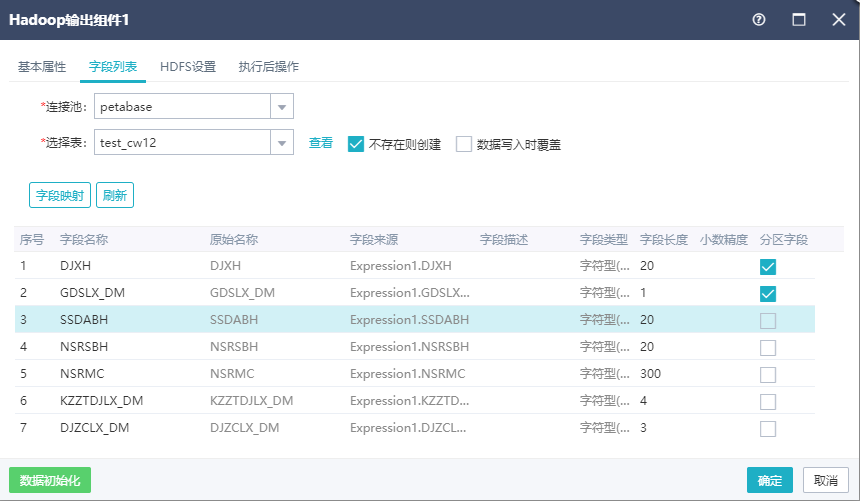
1)分区表设置
表不存在则新建时,在分区字段列,可以勾选任意字段作为分区字段。如果未勾选分区字段,则新建的表为非分区表;勾选了分区字段就是创建分区表。
选择已存在的表时,在分区字段列,会自动加载所有的分区字段。若选择的表不是分区表,则没有分区字段。表已存在时,分区字段列无法勾选。
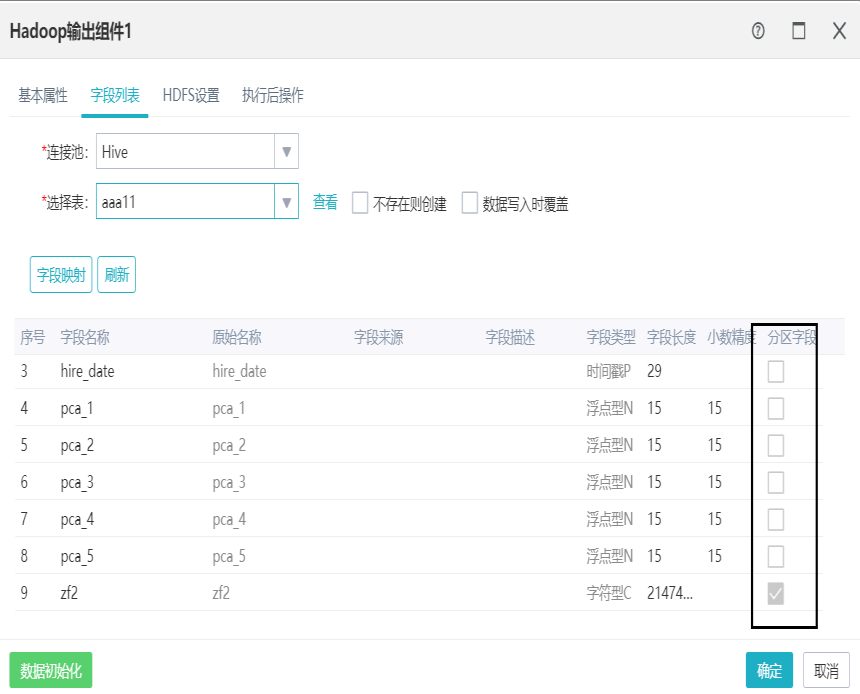
2)外部表设置
用户点击外部表可创建外部表,并指定本地文件存储路径,然后直接使用load data local inpath加载本地文件数据到Hive中,然后在从Hive表抽取数据到其他数据库中。
16.安全脱敏组件
16.1加/解密组件
对选择的字段进行加密或解密,根据输出设置将字段进行输出
字段名:选择需要加/密的字段。
字符集:根据实际情况选择UTF-8/GBK。
方法:选择“加密”或“解密”。
算法:支持SM2和SM4算法。
秘钥:根据实际情况输入。

输出字段界面:
选择需要输出的字段,将传递给后置组件。
16.2脱敏组件
作用:
通过多种脱敏方式对源数据进行脱敏处理,脱敏组件只能处理字符串类型字段。
脱敏方式包括:
0.固定值替换:将所选字段中某个位置,如:任意位置、开头、结尾或者特定位置处的子字符串替换为新字符串;
1.前后缀增补:在所选字段中搜索子字符串,搜索到后在该字符串的前面或者后面添加新字符串;
1.数据模糊化:将所选字段(字符型)从指定起始位置开始进行指定长度的模糊化处理,模糊化后字段内容原字段内容将被替换为“*”;
1.数据裁切:在所选字段中从第0个或者跳过一些字符,从第N个字符开始搜索给定字符串,搜索到后在字符串前面或者后面删除指定字符串个数;
1.MD5处理:将选择的字段(字符型)进行MD5处理;数据库加密
1.哈希处理:将选择的字段进行哈希处理;
1.随机填充:将选择的字段从前或者从后开始填充,填充到指定长度;
1.偏移值加密:将选择的字段先向右偏移(左侧补0的方式)指定位数,然后进行加密处理,加密算法支持:AES和DES。由于用户权限不够,偏移值加密采用的是内存加密的方式。


请先登录