一、推荐依据
类型一:多来源类型(多个元数据推荐一条标准)
情况1、出现大于等于2个同中文名元数据,推荐。
例如:

备注:
中文同名元数据,英文名称取第一个元数据的英文名称
英文同名但不含词根,暂不推荐
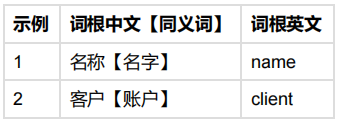
情况2、词根中文及同义词匹配→匹配元数据中文名称→大于等于2个元数据,推荐。
例如:

备注:满足中文匹配后,英文名称直接取词根的英文组合(词根之间使用_ 分隔)
情况3、词根英文及英文缩写→匹配元数据英文名称→大于等于2个元数据,推荐。
例如:

备注:满足英文匹配后,中文名称直接取词根的中文组合(词根之间不分隔)
类型二:关键数据字段类型(一个元数据推荐一条标准:取综合关键程度前100的元数据)
计算关键程度:
l关键程度= 1/3 * 匹配度+ 1/3 * 匹配词根数量+ 1/3 * 关联度(备注:公式中1/3为权重,目前暂定3个数值权重一样)
l匹配度=max(中文匹配词根字符个数/中文字符个数,英文匹配词根字符个数/英文字符个数)
l匹配词根数量=max((中文匹配词根字符个数-中文最小匹配数量)/(中文最大匹配数量-中文最小匹配数量),(英文匹配词根字符个数-英文最小匹配数量)/(英文最大匹配数量-英文最小匹配数量))
l关联度=(关联数-最小关联数)/(最大关联数-最小关联数)
例如:
现有词根:
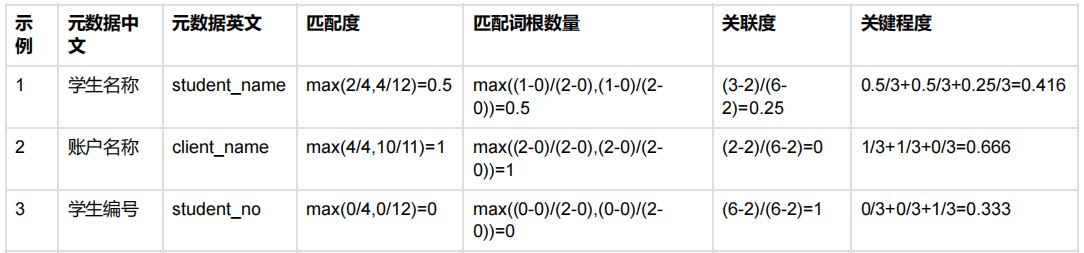
现有字段元数据:

关键程度计算方式计算方式:
l最大中文词根匹配数量2,最小中文词根匹配数量0
l最大英文匹配数量2,最小英文匹配数量0
l最大关联元数据个数6,最小关联元数据个数2
二、推荐结果排序
排序规则:
1. 未采纳>已采纳
2. 多来源类型>关键数据字段类型
3. 来源元数据个数(多来源类型)个数多的在前面
4. 关键程度大的在前面
5. 推荐结果的标准名称升序排序
三、生成标准的填充规则
生成标准的属性填充内容包括:
|标准中文名称
|标准英文名称
|标准集属性中绑定过元数据的属性
只支持以下填充规则:
|标准中文名称:元数据名称为中文时,将元数据名字中匹配上的词根同义词替换为词根,其余未匹配上的文字保留,生成标准中文名称。如元数据为英文,则跟据匹配上的词根中文生成标准中文名称(将“名称”、“编号”、“日期”放在最后位置)。元数据名称中不包含词根的同名匹配的推荐的标准,标准中文名称直接取元数据名称。
|标准英文名称:跟据匹配上的词根英文生成标准英文名称。元数据名称中不包含词根的同名匹配的推荐的标准,标准英文名称直接取元数据代码。
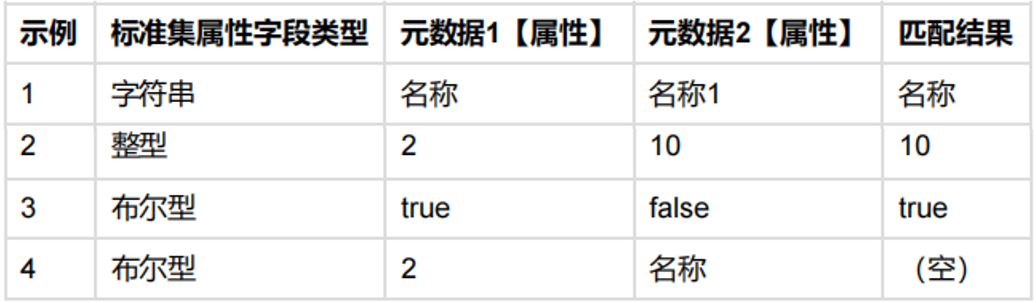
|绑定过元数据的属性:标准集属性字段类型为字符串时:
对应元数据属性
- 元数据名称:取第一个值
- 元数据代码:取第一个值
- 默认值、注释:取第一个
- 是否自增、是否唯一、允许为空:true>false
- 数据类型:同类型取对应值,不同类型取VARCHAR2
- 长度、精度、小数位数:取最大值
|标准集属性字段类型为整型时:
- 长度、精度、小数位数:取最大值,其他均为空
|其他类型均返回为空
例如:


请先登录